
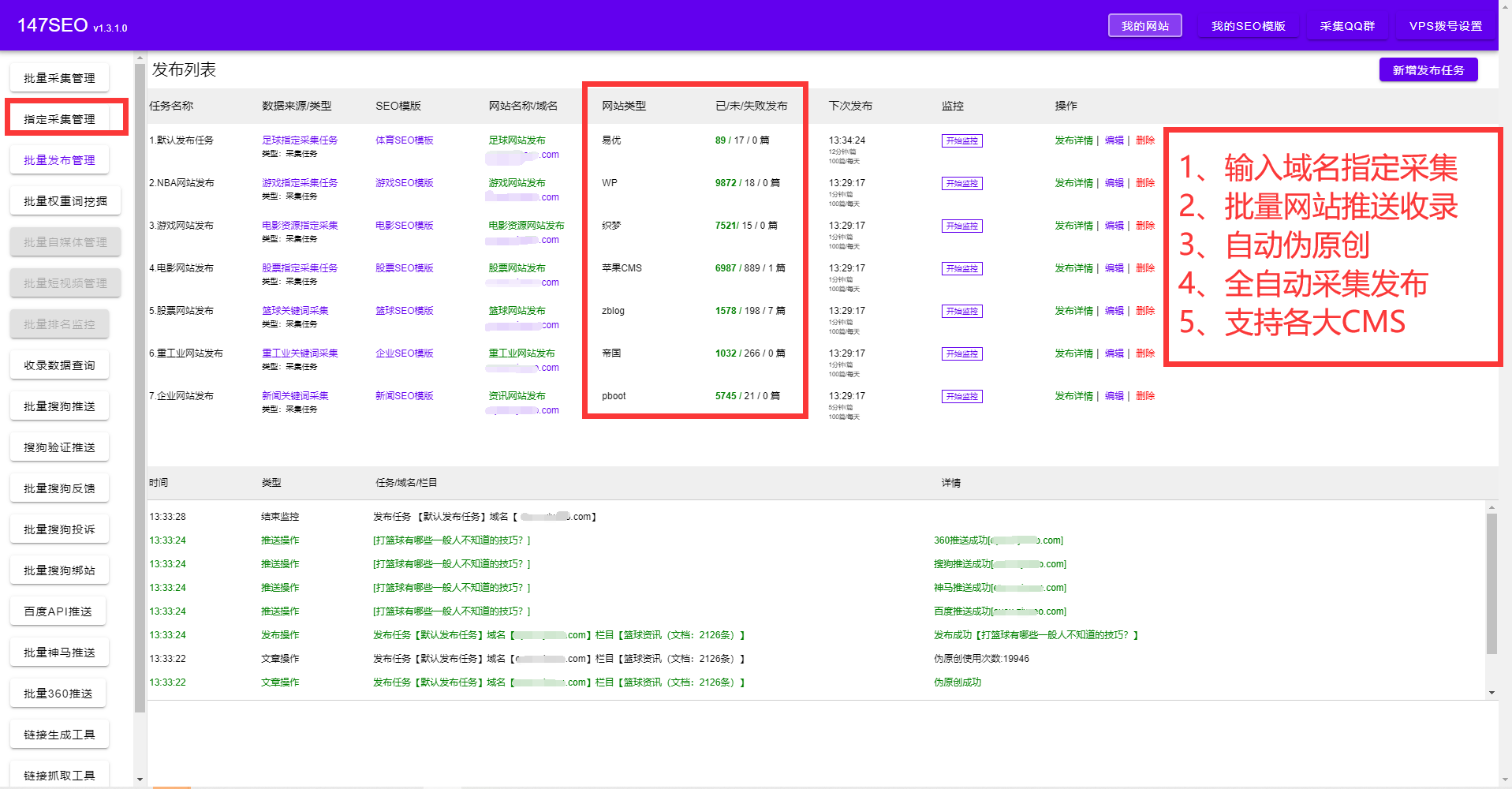
火車頭采集偽原創(chuàng)插件
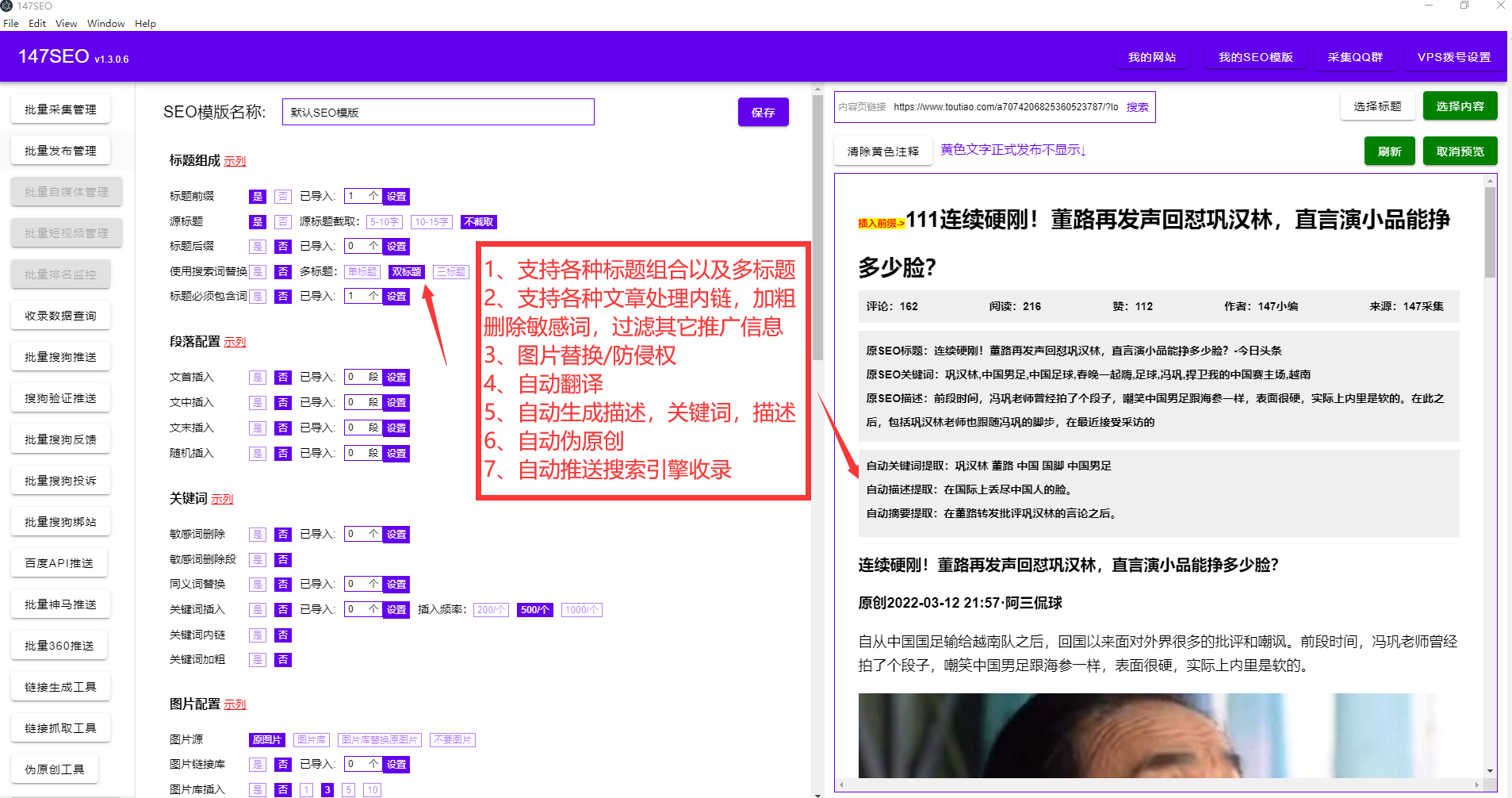
火車頭采集偽原創(chuàng)插件,火車頭采集偽原創(chuàng)插件主要是用NLP自然語言處理,目前NLP已經(jīng)可以做到很多事情了,比如一句話可以分為字和詞,分詞后對詞義進行分析,從而能夠更精確去理解一句話的含義。NLP是人工智能中最重要的環(huán)節(jié)。而火車頭采集偽原創(chuàng)插件,就是利用了NPL自然語言處理,火車頭采集偽原創(chuàng)插件能幫網(wǎng)站持續(xù)產(chǎn)生高質(zhì)量偽原創(chuàng)文章。
火車頭采集偽原創(chuàng)插件的情感分析,指的是對文本中情感的傾向性和評價對象進行提取的過程。火車頭采集偽原創(chuàng)插件情感引擎提供篇章級情感分析。基于上百萬條社交網(wǎng)絡(luò)平衡語料和數(shù)十萬條新聞平衡語料的機器學(xué)習(xí)模型,結(jié)合火車頭采集偽原創(chuàng)插件的半監(jiān)督學(xué)習(xí)技術(shù),正負面情感分析準(zhǔn)確度達到80%~85% 。經(jīng)過行業(yè)數(shù)據(jù)標(biāo)注學(xué)習(xí)后準(zhǔn)確率可達85%~90%。
火車頭采集偽原創(chuàng)插件的文本信息分類將文本按照預(yù)設(shè)的分類體系進行自動區(qū)分。火車頭采集偽原創(chuàng)插件通過搜索引擎網(wǎng)絡(luò)挖掘商業(yè)情報和潛在推廣機會,企業(yè)內(nèi)文本數(shù)據(jù)分析,海量數(shù)據(jù)篩選,資訊分類和自動標(biāo)簽預(yù)測等。基于火車頭采集偽原創(chuàng)插件的語義聯(lián)想、句法分析等技術(shù),通過半監(jiān)督學(xué)習(xí)引擎的訓(xùn)練,只需要進行少量的代表性數(shù)據(jù)標(biāo)注,就可以達到原創(chuàng)級別的預(yù)測準(zhǔn)確率。
火車頭采集偽原創(chuàng)插件的實體識別用于從文本中發(fā)現(xiàn)有意義的信息,例如人名、公司名、產(chǎn)品名、時間、地點等。火車頭采集偽原創(chuàng)插件的實體識別是語義分析中的重要的基礎(chǔ),是情感分析、機器翻譯、語義理解等任務(wù)中的重要步驟。火車頭采集偽原創(chuàng)插件實體識別引擎基于結(jié)構(gòu)化信息抽取算法,F(xiàn)1分數(shù)達到81%,相比于其他高出7個百分點。通過對行業(yè)語料的進一步學(xué)習(xí),可以達到更高的準(zhǔn)確率。
火車頭采集偽原創(chuàng)插件的典型意見引擎將搜索用戶的意見進行單句級別的語義聚合,提取出有代表性的意見。可用于用戶調(diào)研、用戶點評分析和社會熱點事件的意見整理。火車頭采集偽原創(chuàng)插件基于語義的分析引擎在準(zhǔn)確率上有較大的突破,能將含義接近但表述不同的意見聚合在一起,并可通過參數(shù)調(diào)節(jié)聚類的大小獲得更好的效果,與人工整理相比更加快速、準(zhǔn)確。
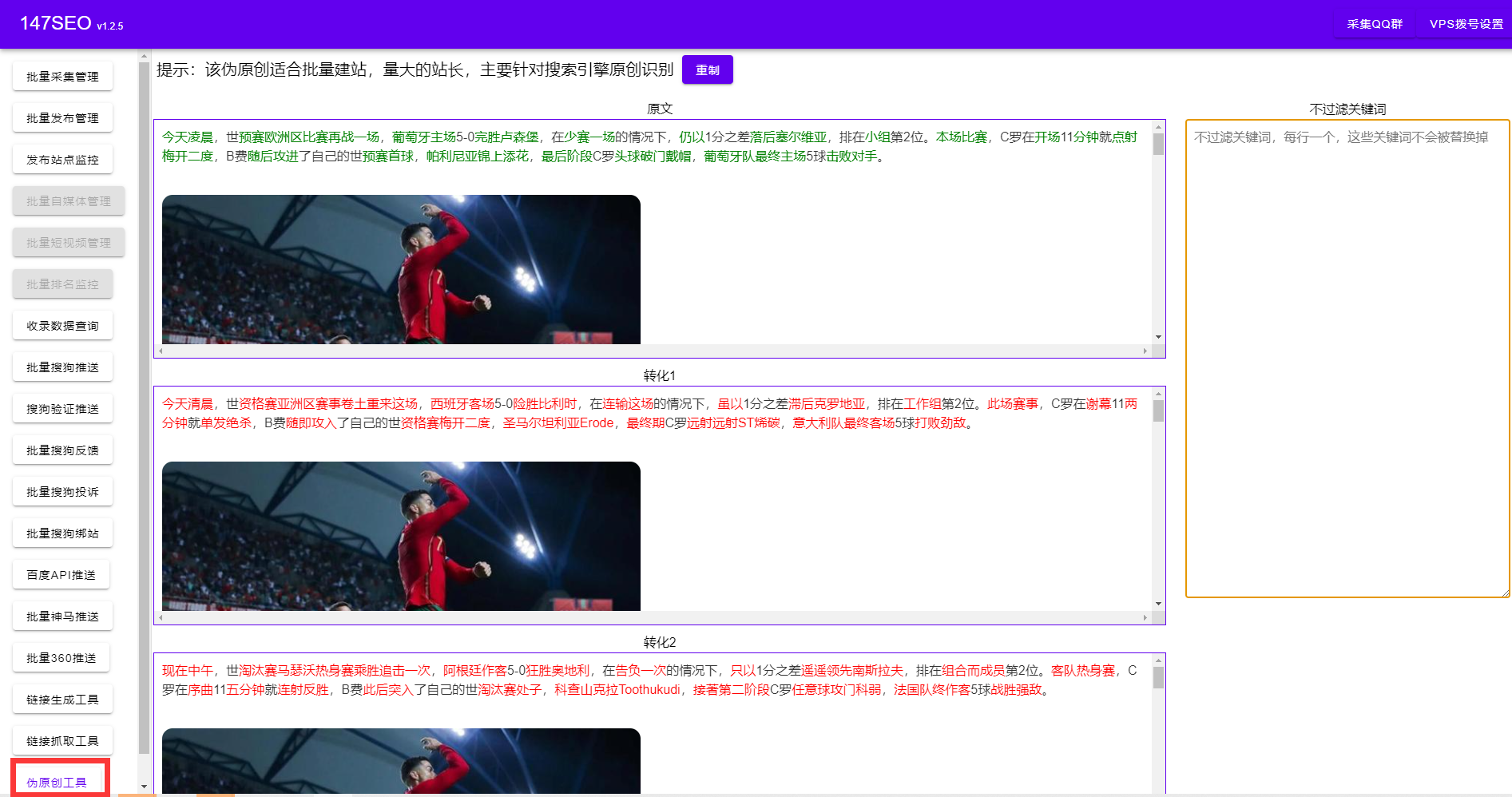
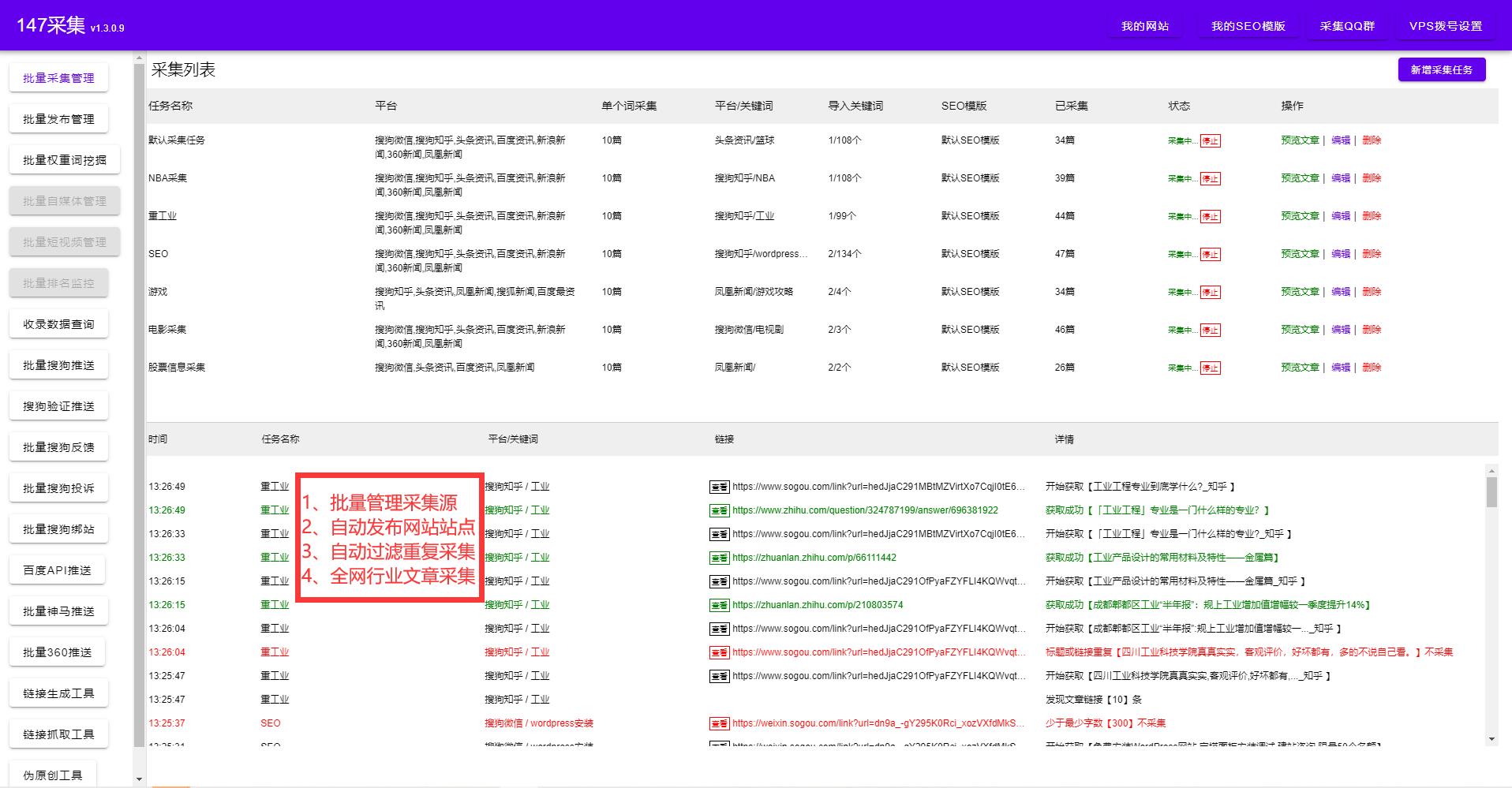
火車頭采集偽原創(chuàng)插件的相似文本聚類指的是機器自動對給定的文本進行話題聚類,將語義上相似的內(nèi)容歸為一類,有助于海量文檔、資訊的整理,和話題級別的統(tǒng)計分析。火車頭采集偽原創(chuàng)插件的文本聚類算法:一方面加入了對語義的擴展,保證同一個意見的不同表述可以被歸納在一起。另一方面又避免了傳統(tǒng)的算法需要預(yù)先設(shè)定聚類總數(shù)的困難,基于數(shù)據(jù)的分布自動選擇合適的閾值。
火車頭采集偽原創(chuàng)插件的關(guān)鍵詞提取引擎從一篇或多篇文本中提取出有代表性的關(guān)鍵詞。火車頭采集偽原創(chuàng)插件的關(guān)鍵詞提取技術(shù)綜合考慮詞語在文本中的頻率,和詞語在千萬級背景數(shù)據(jù)中的頻率,選擇出最具有代表性的關(guān)鍵詞并給出相應(yīng)權(quán)重。

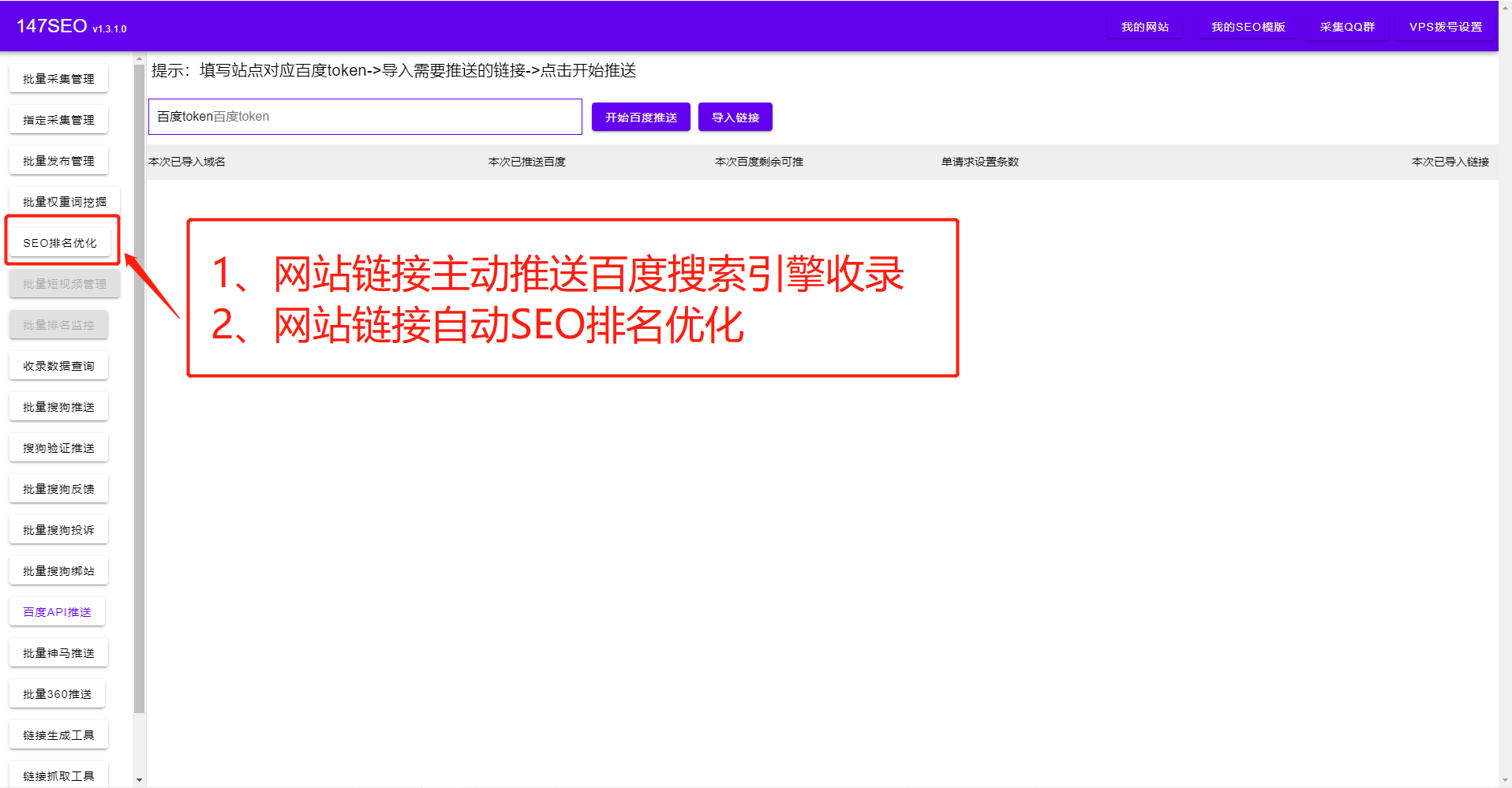
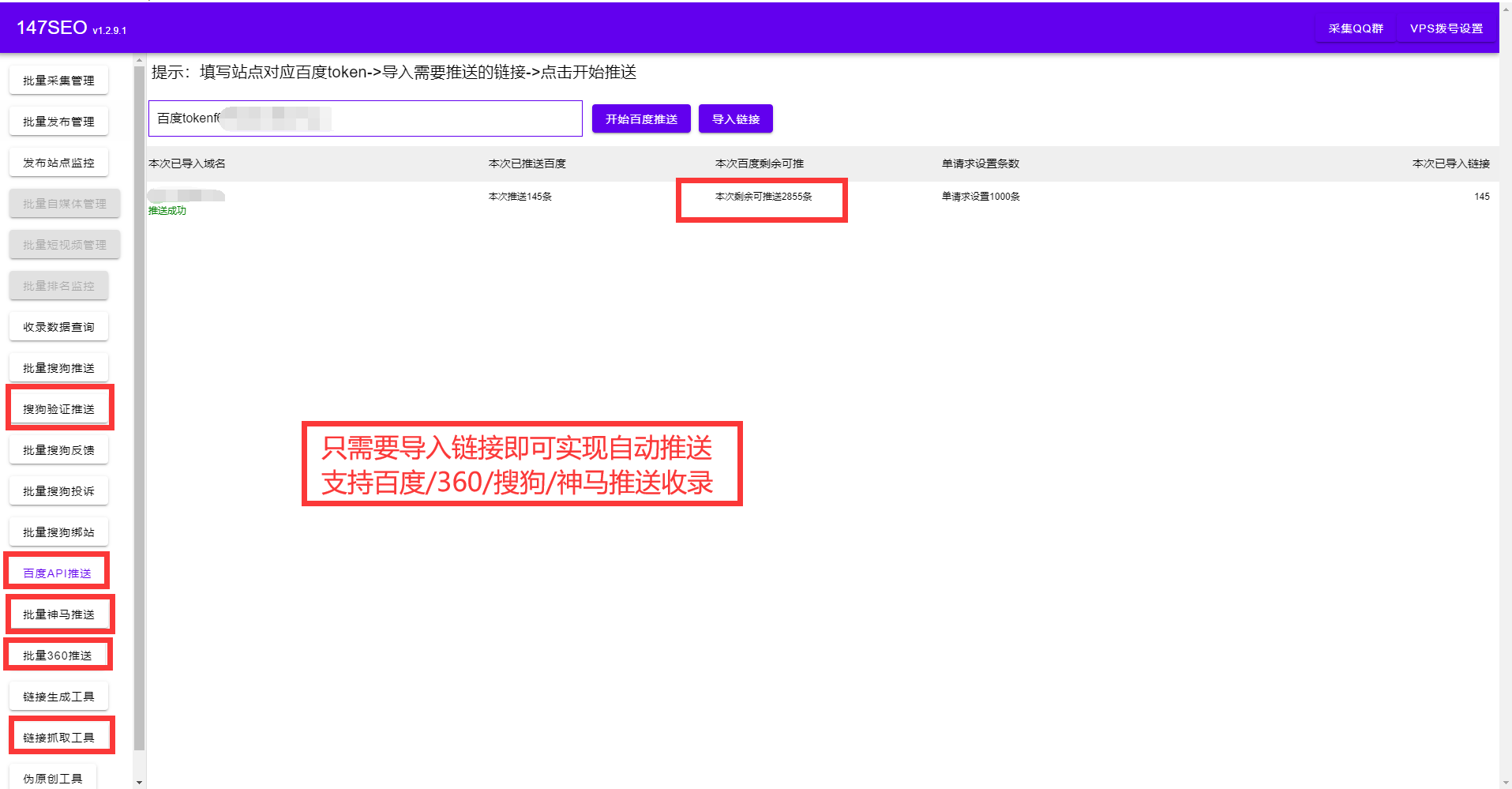
站長們之所以要用專業(yè)的火車頭采集偽原創(chuàng)插件,是因為站長的網(wǎng)站上有大量的文章需要采集發(fā)布偽原創(chuàng),而人工手動的方式往往效率太低。火車頭采集偽原創(chuàng)插件抓取文章時,不僅可以抓取文字,還可以下載圖片,保證不遺漏原文的所有內(nèi)容,同時對采集到的內(nèi)容進行智能的AI偽原創(chuàng)處理,以增加網(wǎng)站文章的發(fā)布量,和對搜索引擎的友好度,增加網(wǎng)站的收錄排名。



