
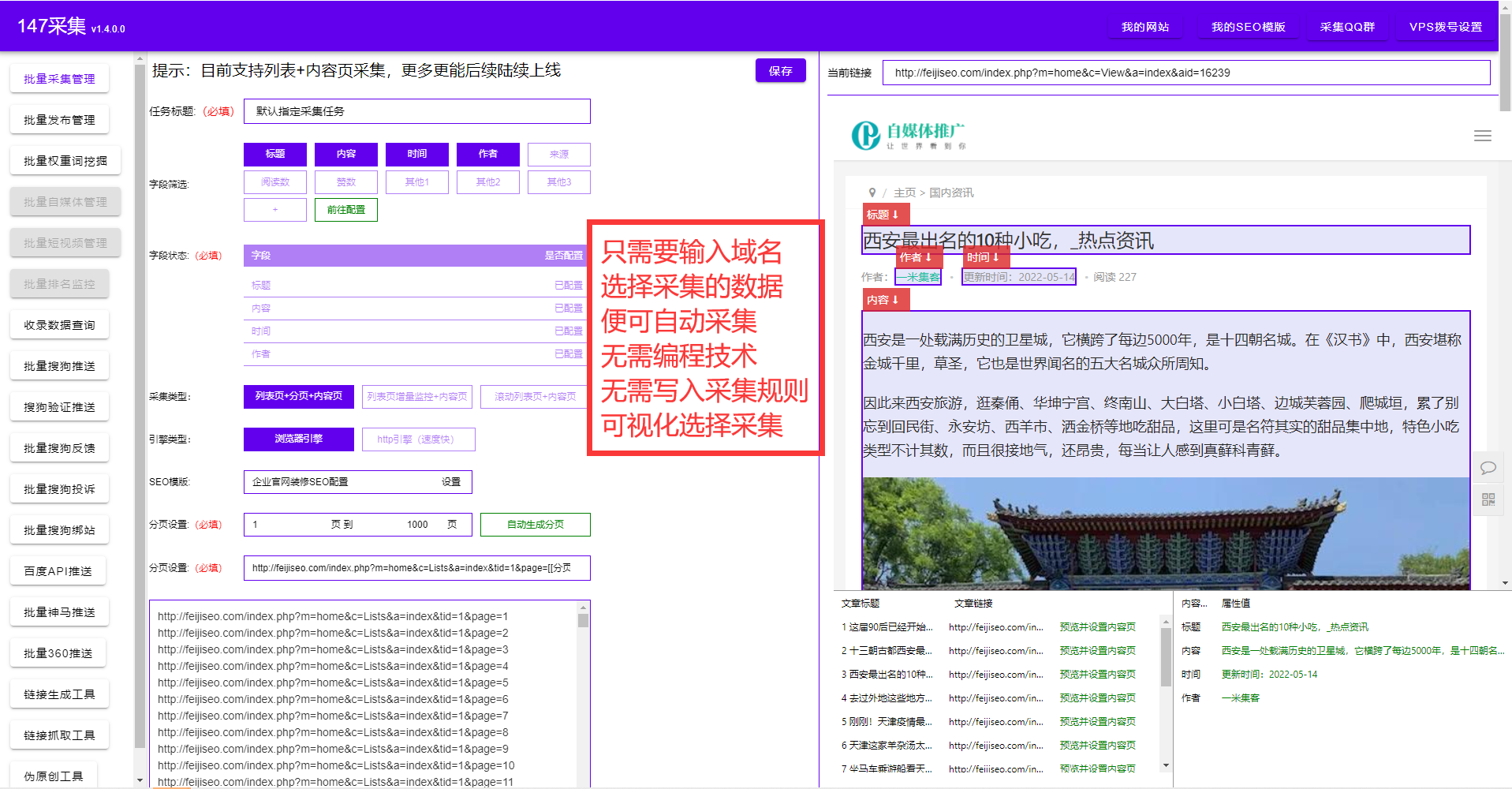
后羿采集器怎么用?后羿采集器教程?
后羿采集器怎么用?后羿采集器教程?相信用過后羿采集器的朋友們都知道,后羿采集器是需要一定的編程能力,不然很難用好后羿采集器,這里為了照顧更多不懂的小白朋友分享一款免費的采集器。只需要輸入域名,點選你需要采集的內容,就輕松地完成了數(shù)據采集,詳細參考圖片。本期教程為后羿采集器更多的是介紹后羿采集器的教程。
如果自動識別效果不符合您的要求,您可以通過“手動點選列表”和“編輯列表Xpath”兩種方式來修改識別結果。
手動點選列表的操作步驟如下:
后羿采集器教程第一步:點擊“手動點選列表”的選項
后羿采集器教程第二步:點擊網頁中列表的第一行的第一個元素
后羿采集器教程第三步:點擊網頁中列表的第二行的第一個元素
但是偶爾也會發(fā)生識別結果錯誤的情況,原因通常包括以下幾種:
(1)網頁加載速度過慢,軟件自動識別結束之后才出現(xiàn)分頁按鈕
(2)頁面中存在多個分頁按鈕,軟件最終只會選擇其中的一個
(3)在滾動加載和分頁按鈕同時存在的情況中,軟件自動滾動多次之后分頁按鈕仍未出現(xiàn)。
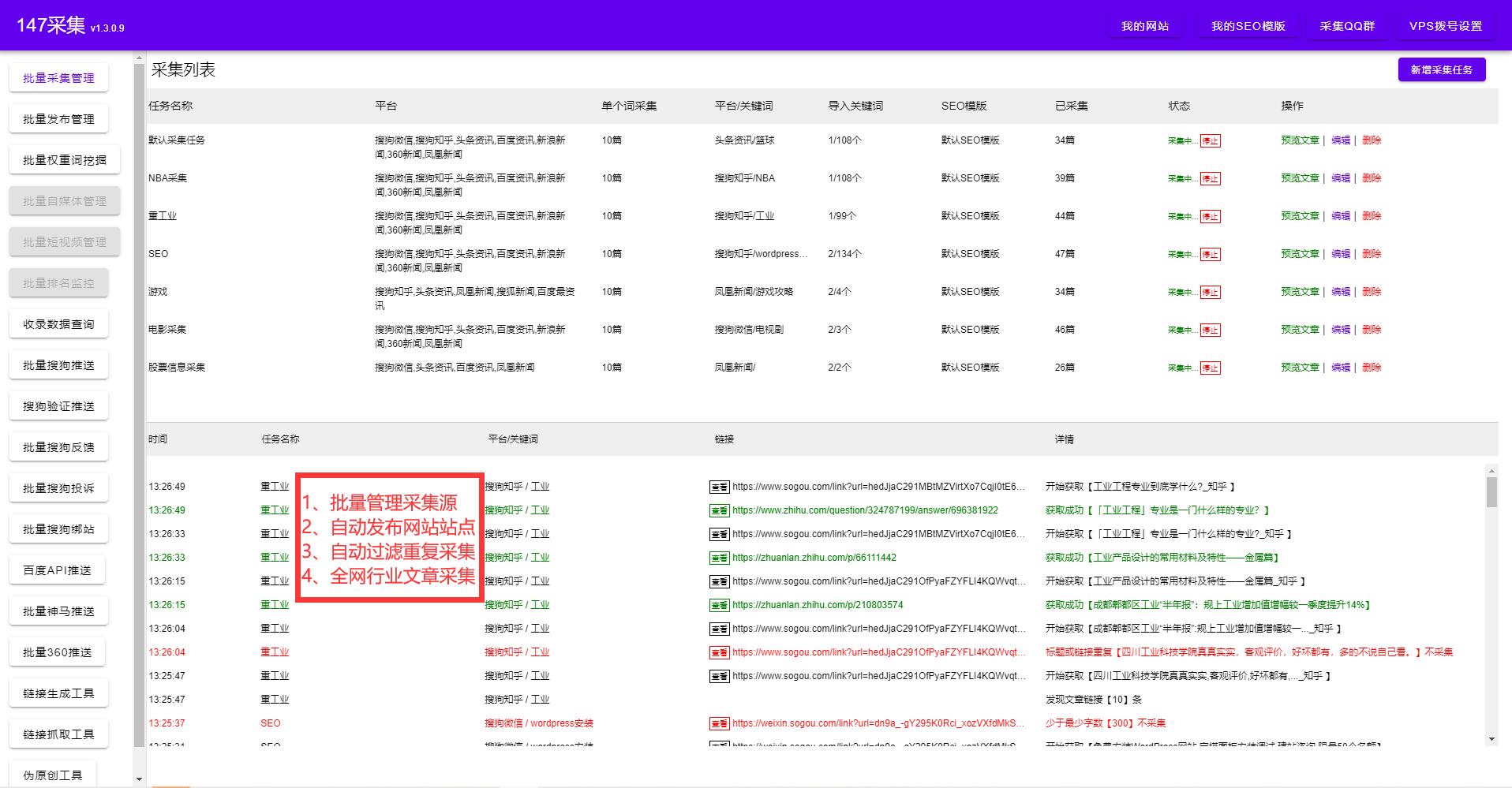
(4)當前頁面中的分頁按鈕軟件暫時未兼容
后羿采集器教程適合一開始沒有分頁按鈕,需要通過滾動網頁多次后才能加載出分頁按鈕的網頁,或者已經顯示了下一頁按鈕,但是當前網頁內容未展示完畢,需要滾動網頁多次后才能顯示當前網頁的全部內容。
這種分頁類型比較難識別,盡管軟件在自動識別時會嘗試自動滾動,但是這個滾動的次數(shù)和當前網頁所需的滾動次數(shù)可能不一致,所以這種類型的分頁通常需要加入一些人工操作。
主要分為以下幾種情況:
第一種:識別出滾動加載,但是未識別出分頁按鈕
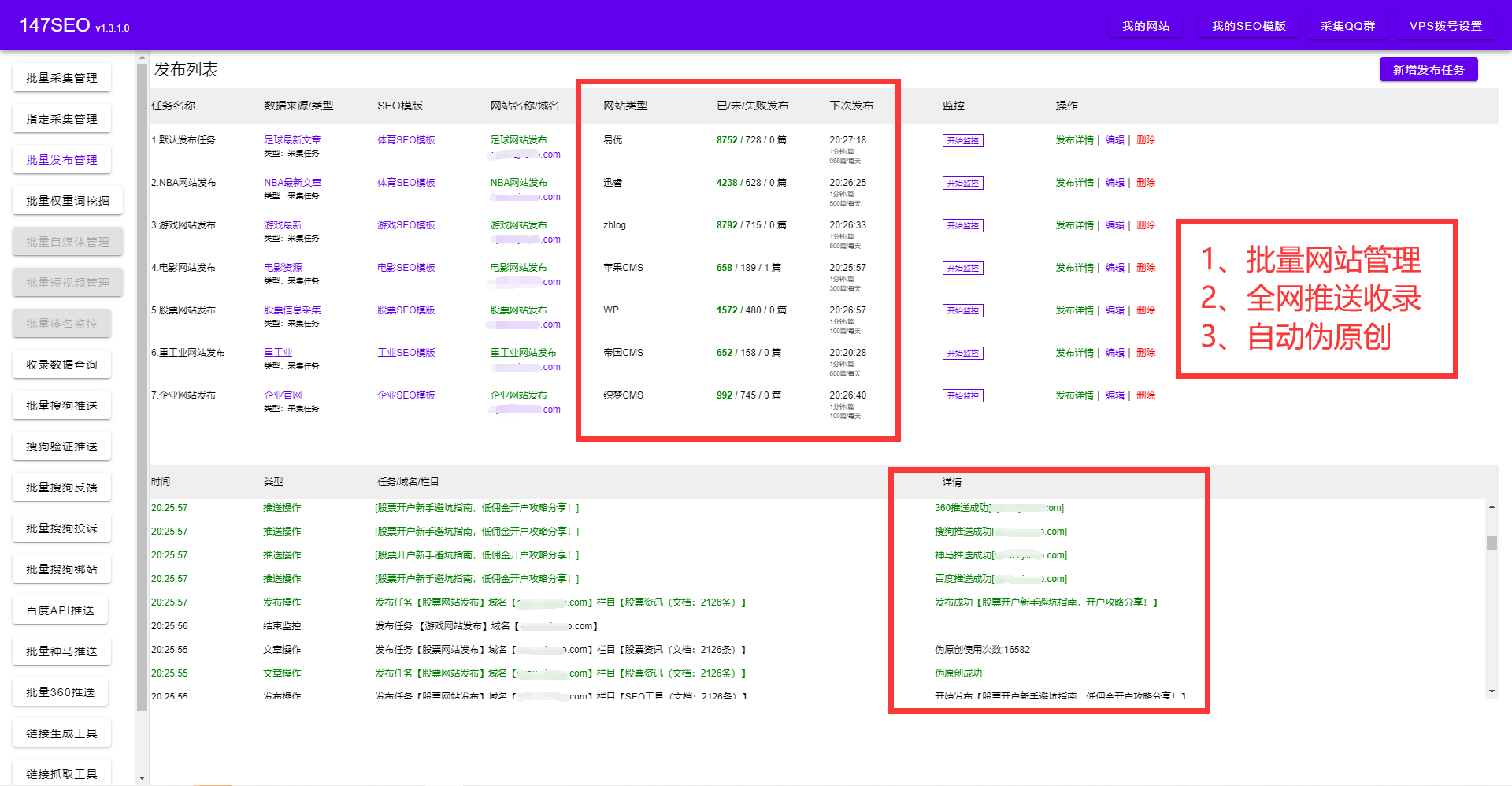
后羿采集器教程合并字段有兩種辦法,一種是點擊一條需要合并的字段,右擊選擇“合并字段”,然后在頁面中選擇需要合并的字段,這種方式適合兩個字段的合并。在合并字段中,用戶可以設置兩個字段內容之間的分隔符,如果不需要分隔符,在分隔符部分直接設置為空白就好。如果要修改字段中提取的內容,或者在添加新字段時進行提取對象的設置,可以點擊“在頁面中選擇”或者字段上的瞄準器圖標,然后在網頁中點擊需要的數(shù)據
Xpath一種路徑查詢語言,簡單的說就是利用一個路徑表達式找到我們需要的數(shù)據在網頁中的位置。有編程基礎的用戶可以使用此功能進行采集對象的定位。
不同的數(shù)據需要設置不同的取值屬性,在設置新字段的時候,字段的取值默認的是文本字段,一般情況下,在您選取新數(shù)據時,后羿采集器會自動幫你判斷好字段屬性,您不需要另外設置,但如果出現(xiàn)判斷失誤的情況下,您可以自己設置字段的取值屬性。
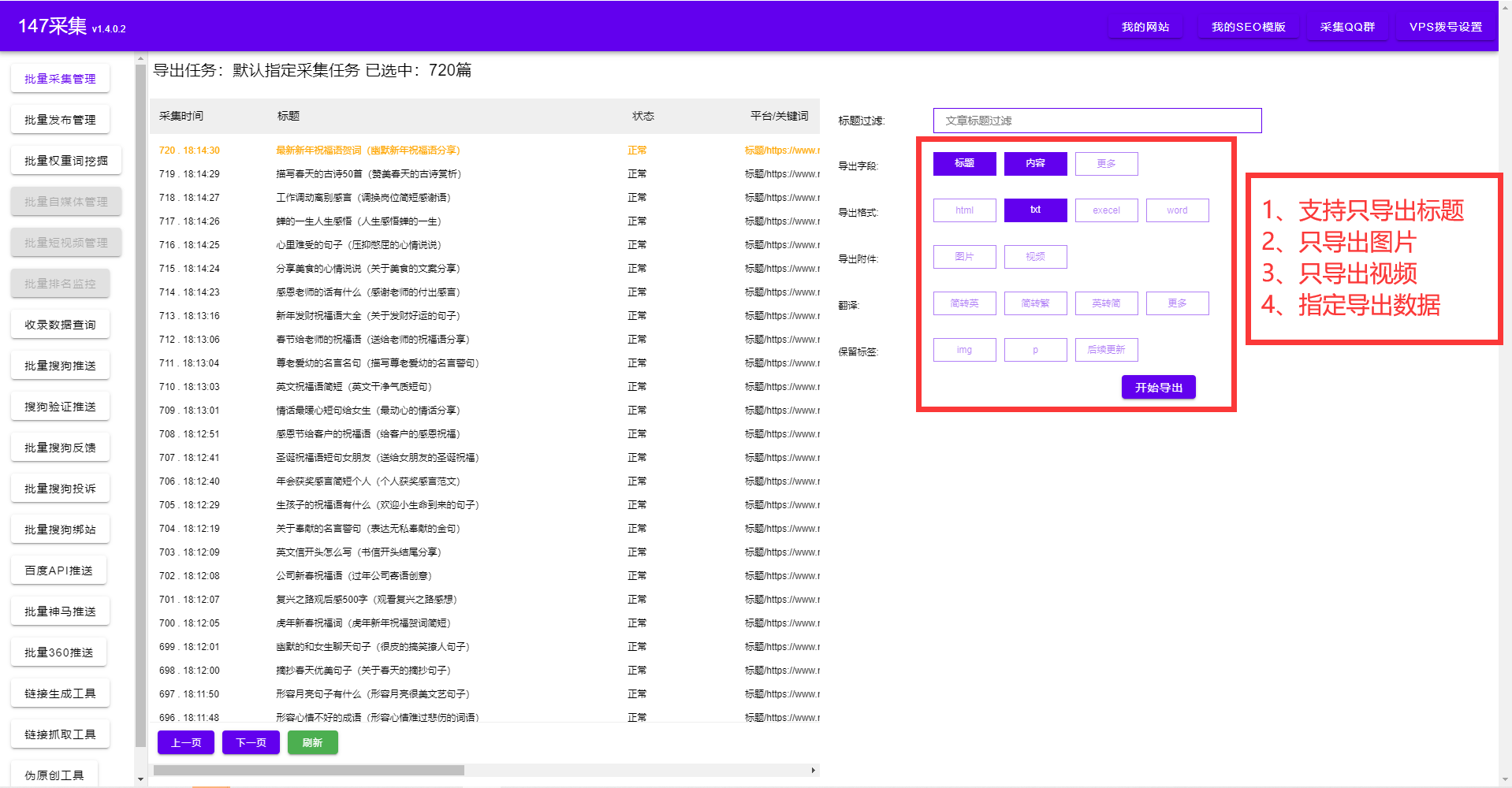
后羿采集器教程提取文本:適合普通的文本數(shù)據
后羿采集器教程提取內部HTML:適合提取不包括內容自身的HTML
后羿采集器教程提取外部HTML:適合提取包括內容自身的HTML
后羿采集器教程提取鏈接地址:適合提取鏈接的數(shù)據
后羿采集器教程提取圖片等媒體地址:適合提取圖片等媒體資源
后羿采集器教程提取輸入框內容:適合提取輸入框的文字,多用于關鍵詞采集時使用
后羿采集器教程在數(shù)據采集過程中,如果需要采集一些特殊字段,如采集時的時間、當前網頁標題、當前網頁URL等,這些字段無法直接在網頁中提取,那么可以使用“改為特殊字段”功能進行字段設置,通常我們會新建字段,然后把字段改為特殊字段,我們也可以直接把其他字段改為特殊字段。

在設置采集任務的過程中,有時候我們會遇到一些不需要采集的數(shù)據,如某些數(shù)值為空的數(shù)據或者包含某些字符的數(shù)據,后羿采集器教程從而在一定程度上影響了采集速度和效果,針對這種情況我們可以使用數(shù)據篩選功能,避免采集到無效數(shù)據。
后羿采集器教程流程圖模式中,“數(shù)據篩選”功能在提取數(shù)據組件菜單欄的右上角,,點擊之后會打開篩選條件設置窗口,如下圖所示。(如果流程圖中有多個提取數(shù)據組件,數(shù)據篩選是共享的,在任意一個提取數(shù)據組件中打開設置都可以)



