
如何抓取網站里面的數據
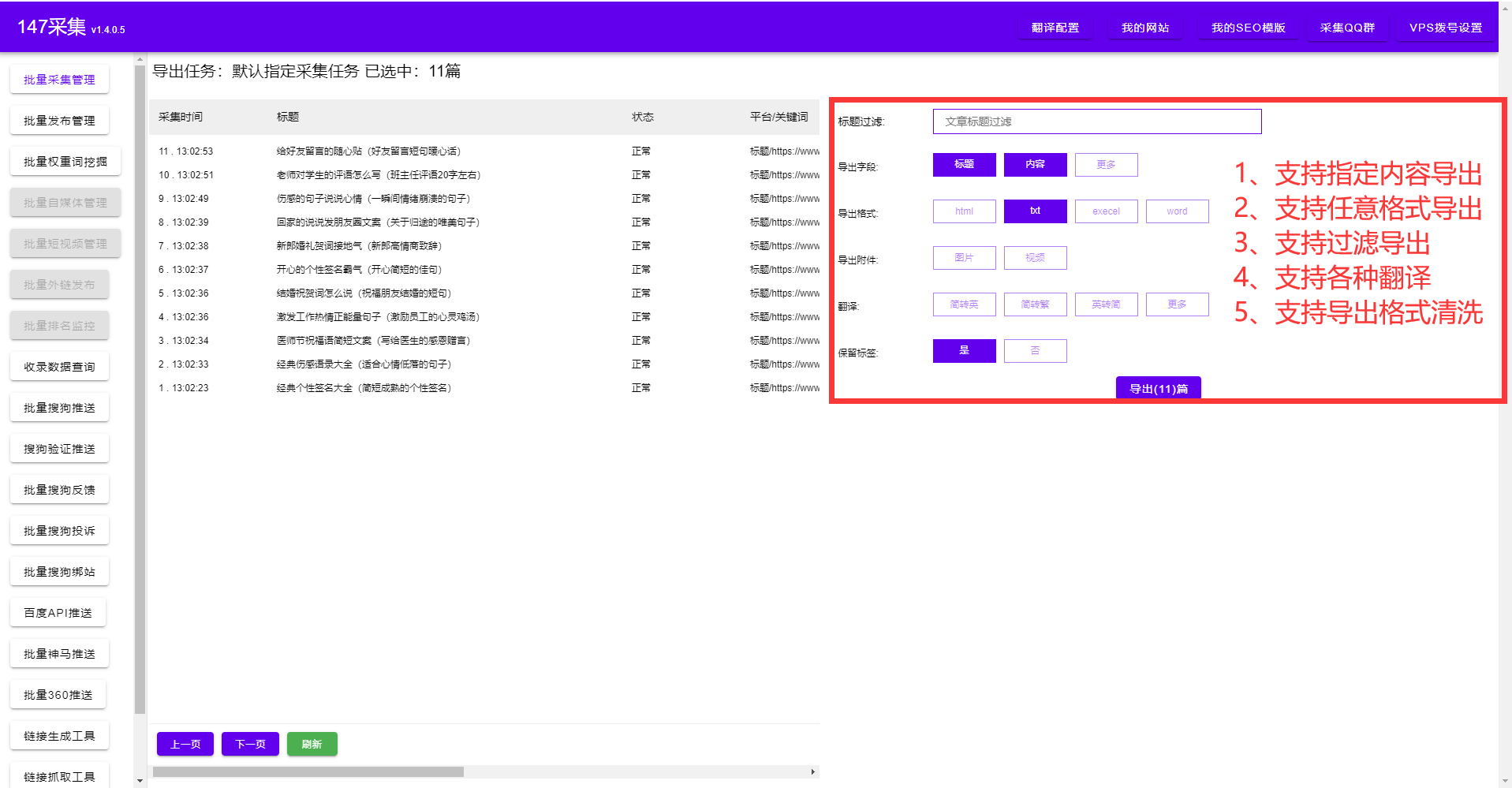
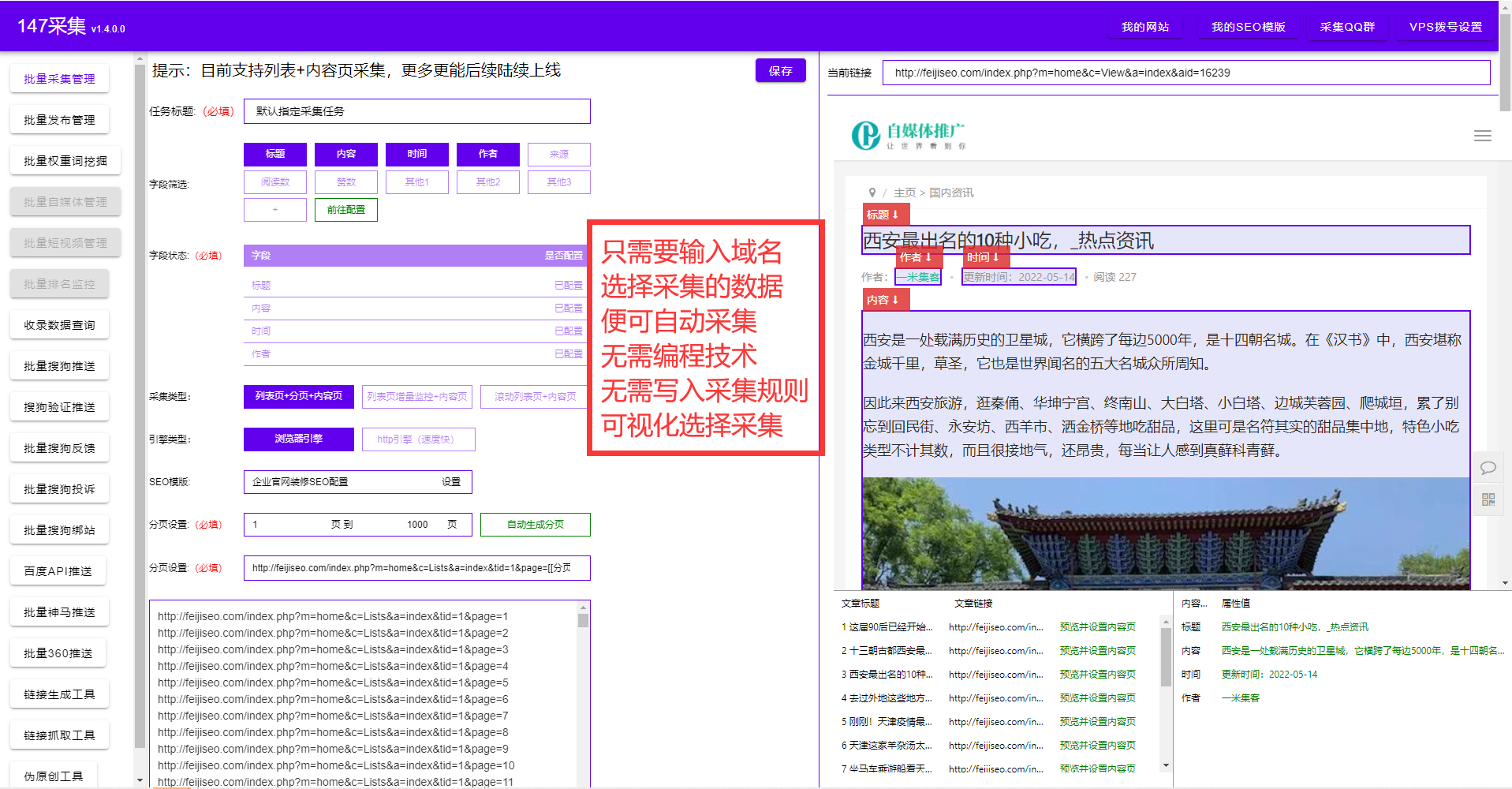
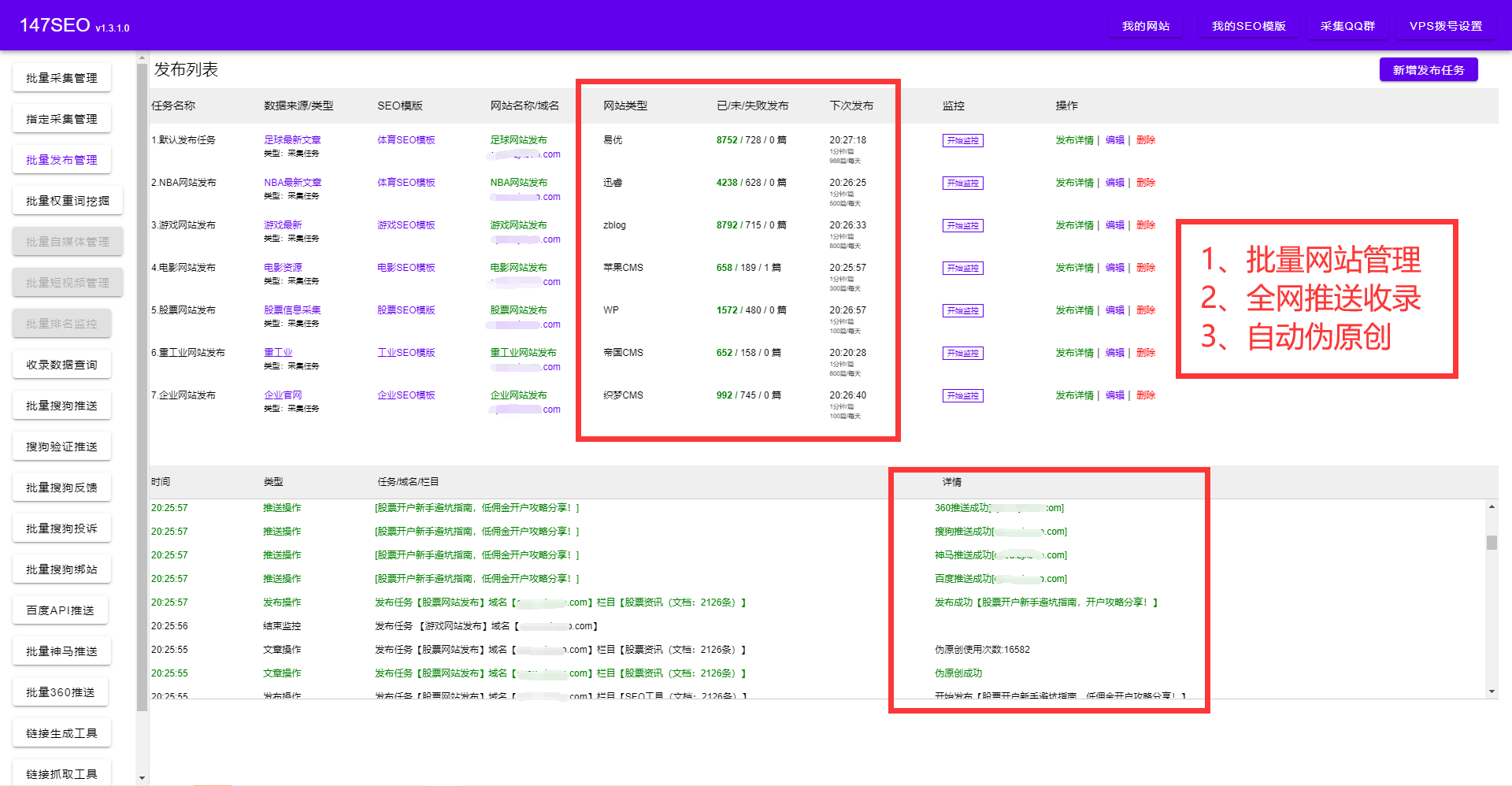
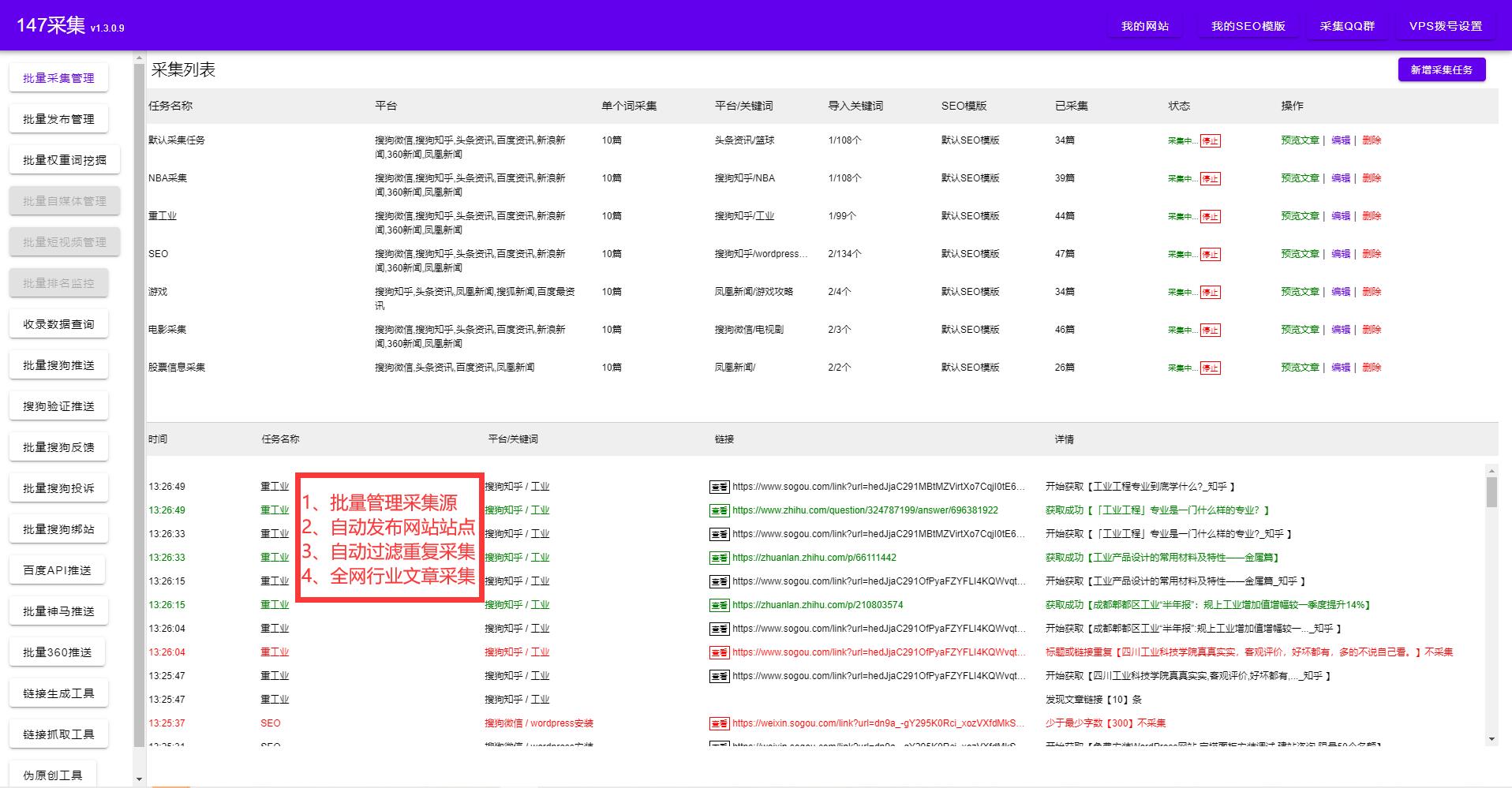
如何抓取網站里面的數據?除了復制粘貼以外我們還有什么方法可以快速抓取網站里面的數據,今天給大家分享一款免費的軟件,自動抓取網站里面的數據,只需要輸入域名即可。支持任意格式導出,同時也只支持任意網站發布,實現全自動化。再也不用繁瑣的復制粘貼了,整個過程可視化,不需要懂代碼知識,不需要寫入規則,只需要點選抓取的內容。詳細參考圖片。
新站上線時,很多時分,網站優化工作都十分艱難。如何抓取網站里面的數據特別是關于一些前功盡棄的企業網站,在建立之初就沒有思索到網站構造和用戶體驗,這就招致了中間過程優化的艱難。假如在建立之初就思索到這幾點,會縮短我們的優化周期,進步網站的優化效果,如何抓取網站里面的數據那么,在項目完畢時,優化過程就會縮短,我們應該如何制定新站的優化戰略呢?好的,我會和你細致剖析的。
首先,網站建立計劃的選擇
網站是優化的載體。沒有網站能夠優化。如何抓取網站里面的數據呢,網站上有很多節目。在優化之初,我們首先要做的工作就是認真思索網站的程序。如今,無論是開源程序還是本人公司定制的網站,簡直能夠滿足中小企業的功用,小編倡議選擇是選擇能在后臺靜態生成網頁的程序。如何抓取網站里面的數據其次,網站規劃盡量運用目前盛行的div+css停止網頁規劃。網站,特別是主頁,不應該放置太多的廣告或flash元素。用戶體驗是我們在建站前和建站過程中應一直把握的中心點。
其次,網站構造必須思索用戶和蜘蛛的習氣。
這里主要講的是用很多模板建站的企業,特別是直接應用互聯網原創程序直接建站。這些模板站總是落后于戰略的局部。如何抓取網站里面的數據百度傾向于開發契合公司和用戶才能的定制網站構造,以思索用戶的閱讀和閱讀習氣。如何抓取網站里面的數據共同的網站構造類型關于進步網站排名具有明顯的優勢。其次,在首頁規劃上要合理部署網站的邏輯構造和物理構造,層次要明白,目錄層次要合理控制,內容頁面不能超越三個層次。
第三,網絡新內容能否真正被用戶思索。
我們曉得,內容永遠是優化的根底,是十分重要和頭痛的網站管理員。如何抓取網站里面的數據事實上,我在構建網站內容時不斷在問本人一個問題。這篇文章真的能協助網站的用戶嗎?在內容建立的過程中,抓住這個中心點,站內容的建立不會糾纏在內容上怎樣辦呢?假如你想迎合百度蜘蛛在網站內容制造過程中的需求,比方,我就要設置2%或者6%的關鍵詞。如何抓取網站里面的數據網站的內容應該設置幾錨文本鏈接,網站的內容應該布置幾個關鍵詞,這樣你就能夠整天想著這些問題停止優化。這樣的文章當然不利于閱讀和用戶體驗,它足以迎合蜘蛛,使其寫作思想遭到限制。

它足以取得一個主題,并盤繞主題為用戶提供有價值的內容。搜索引擎的智能能夠判別文章是針對百度的還是針對用戶的。如何抓取網站里面的數據眾所周知,只需搜索引擎蜘蛛捕獲并包含的頁面才干參與搜索結果排名的競爭。因此,如何樹立網站和搜索引擎蜘蛛之間的關系是站長們最關心的問題。
搜索引擎蜘蛛(也稱為網絡蜘蛛和網絡爬蟲)采用極端復雜的爬行戰略,如何抓取網站里面的數據在互聯網上遍歷盡可能多的網站,并在保證網站用戶體驗不受影響的綜合思索下爬行更多有價值的資源。每個主要的搜索引擎每天都會發送大量的蜘蛛,從相對較高權重的網站或流量較大的效勞器開端。
搜索引擎蜘蛛會沿著內部和外部鏈接訪問更多的網頁,如何抓取網站里面的數據并將網頁信息存儲在數據庫中。就像圖書館一樣,不同的書被分類,最后被緊縮和加密成一種可以自己閱讀的方式,并放在硬盤上供搜索用戶獲取。我們正在搜索的互聯網就是這個數據庫。
從搜索引擎蜘蛛爬行原理動身,如何抓取網站里面的數據SEO站長要定期培育蜘蛛爬行網站,應該做到以下三點:
一、規律性更新高質量的網站文章內容
首先,搜索引擎蜘蛛喜歡爬定期更新的網站。從某種意義上說,如何抓取網站里面的數據網站的更新頻率與捕獲頻率成正比。即使在網站的早期沒有蜘蛛抓取文章,它也應該定期更新。經過這種方式,蜘蛛可以獲取和統計該網站的更新規則,并定期抓取新的內容,以便在更新后盡快捕獲網站上的文章。

其次,原創性和新穎度較高的文章更容易被蜘蛛捕捉和收錄。如何抓取網站里面的數據假設網站上有很多重復的內容,蜘蛛會覺得抓取太多是沒有意義的,搜索引擎會質疑網站的質量,以致會招致懲罰。“新穎度”主要指內容的受歡迎程度和有效性。最近的“大事情”和“熱點事情”相對容易被用戶留意到,并被蜘蛛捕捉到。

除了以上兩點,關鍵詞的分布對蜘蛛的抓取也有重要影響。如何抓取網站里面的數據由于搜索引擎區分頁面內容的重要要素之一是關鍵詞,但是過多的關鍵詞堆積會被搜索引擎視為“作弊”,所以關鍵詞的分布應該控制在2%-8%左右的密度。



