
在當今信息爆炸的時代,原始的數據早已不再是問題,問題在于如何有效地獲取這些數據并發掘其中的價值。而爬蟲數據量的概念應運而生,它代表著通過網絡爬蟲獲取的數據的規模和豐富程度。通過爬蟲技術,我們可以收集到海量的數據,深入挖掘其中的價值,為各行各業的決策提供支持。
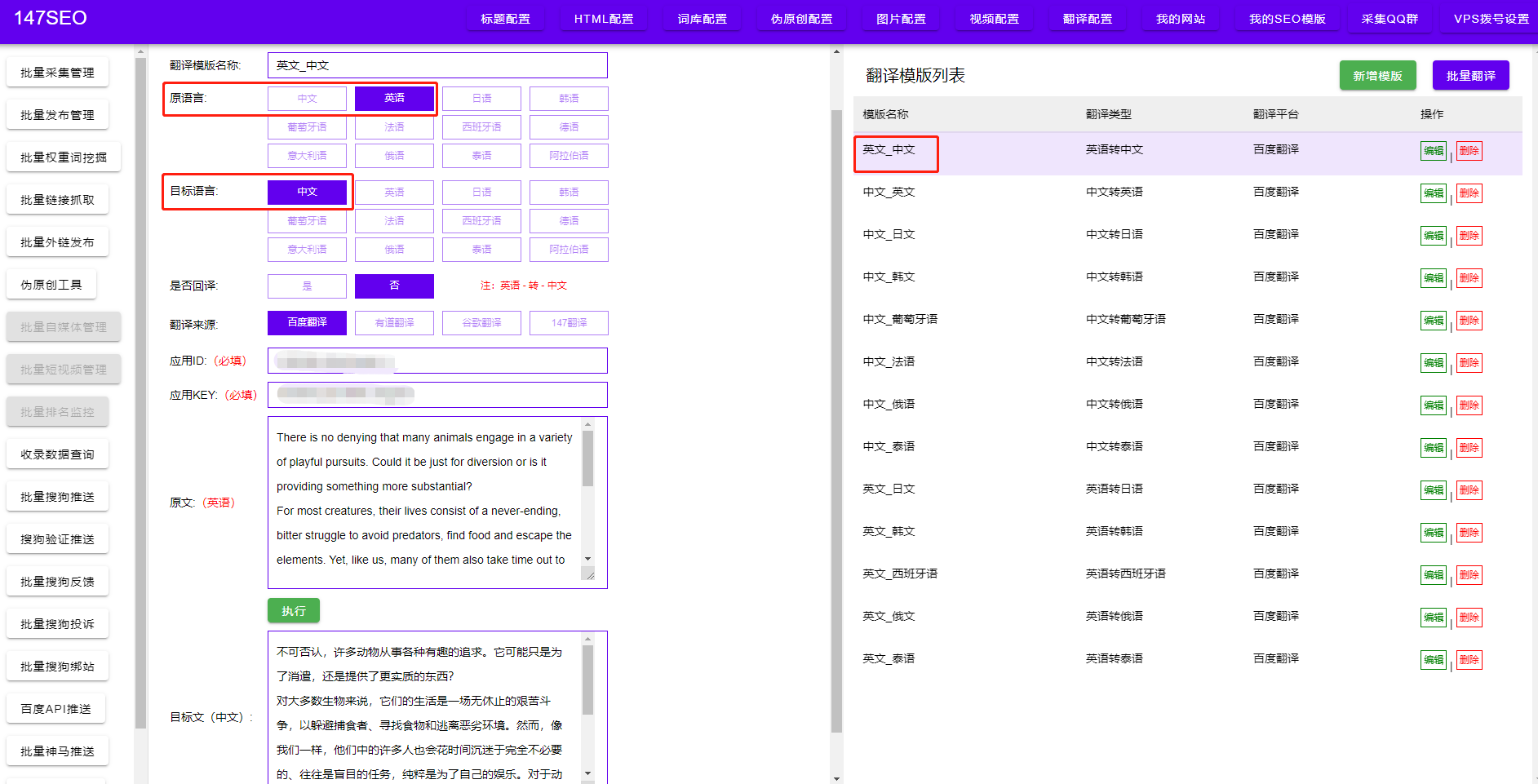
爬蟲數據量的重要性不言而喻。首先,它為數據挖掘提供了基礎。數據挖掘是通過分析和挖掘數據中的隱藏模式、關聯關系和趨勢,以發現有用信息的過程。有了爬蟲數據量的支持,我們可以更好地進行數據挖掘,從而揭示出一些隱藏的商機、消費者行為模式以及市場趨勢等。而這些信息對于企業的決策制定和業務發展具有重要意義。
其次,爬蟲數據量對于數據分析也有著巨大的幫助。數據分析是利用統計學和計算機科學的方法,以分析數據、提取出有價值的信息和模式,并進行合理的預測和決策的過程。通過爬蟲技術采集到的數據,可以為數據分析提供豐富的數據源,從而更好地進行數據建模、特征提取和異常檢測等工作。
此外,爬蟲數據量還為網站抓取和內容分發提供了支持。相信大家都有類似的經歷,當我們在搜索引擎上輸入關鍵詞進行搜索時,搜索引擎就會從海量的網頁中抓取和展示相關的內容。而這些網頁的內容正是通過爬蟲技術從各個網站中抓取得來的。爬蟲數據量的增加,意味著獲取到的相關內容也將更為豐富和準確,從而提升了搜索引擎的用戶體驗。
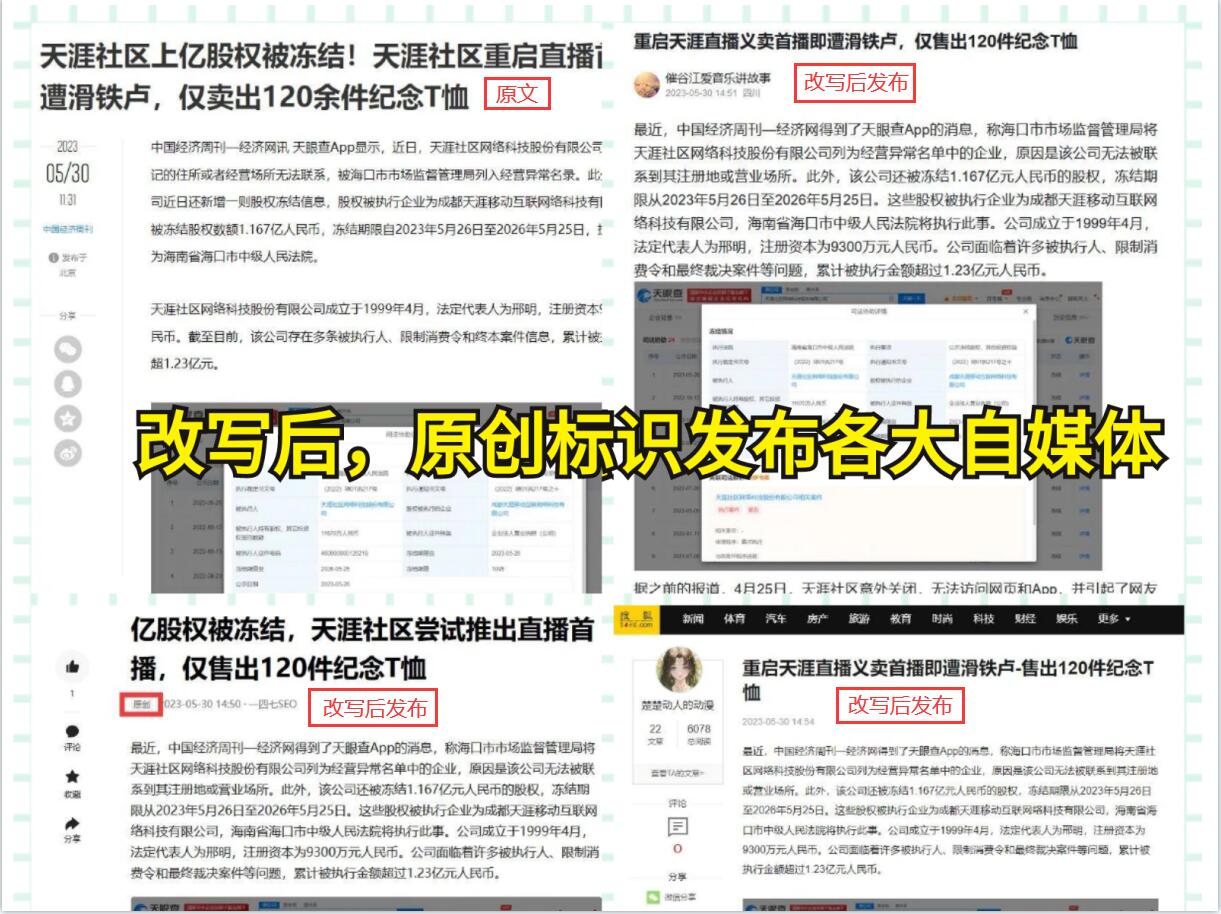
在實際應用中,爬蟲數據量的獲取離不開網絡爬蟲技術的支持。網絡爬蟲是一種自動化的程序,能夠模擬瀏覽器訪問網站,獲取網頁內容,并將其保存下來以供后續分析和處理。通過設置爬蟲的規則和策略,我們可以實現從一系列網頁中爬取感興趣的數據,并將其保存為結構化的數據形式,如JSON、CSV等。
綜上所述,爬蟲數據量對于數據挖掘、數據分析和網站抓取等方面都具有重要意義。通過利用爬蟲技術,獲取大量的數據,我們可以更好地發現有價值的信息和商機,為各行各業的發展提供有力支持。但是值得注意的是,爬蟲技術需要合法合規進行,遵守相關的爬蟲道德和規則法規,在收集和使用數據時需謹慎對待,確保數據的安全和合法性。



