
抓取數據是現代社會信息爆炸時代的一項重要任務。隨著互聯網的快速發展,數據的獲取變得越來越容易,但如何高效地處理和分析這些數據卻是一個挑戰。為了解決這個問題,抓取數據的工具方法應運而生。
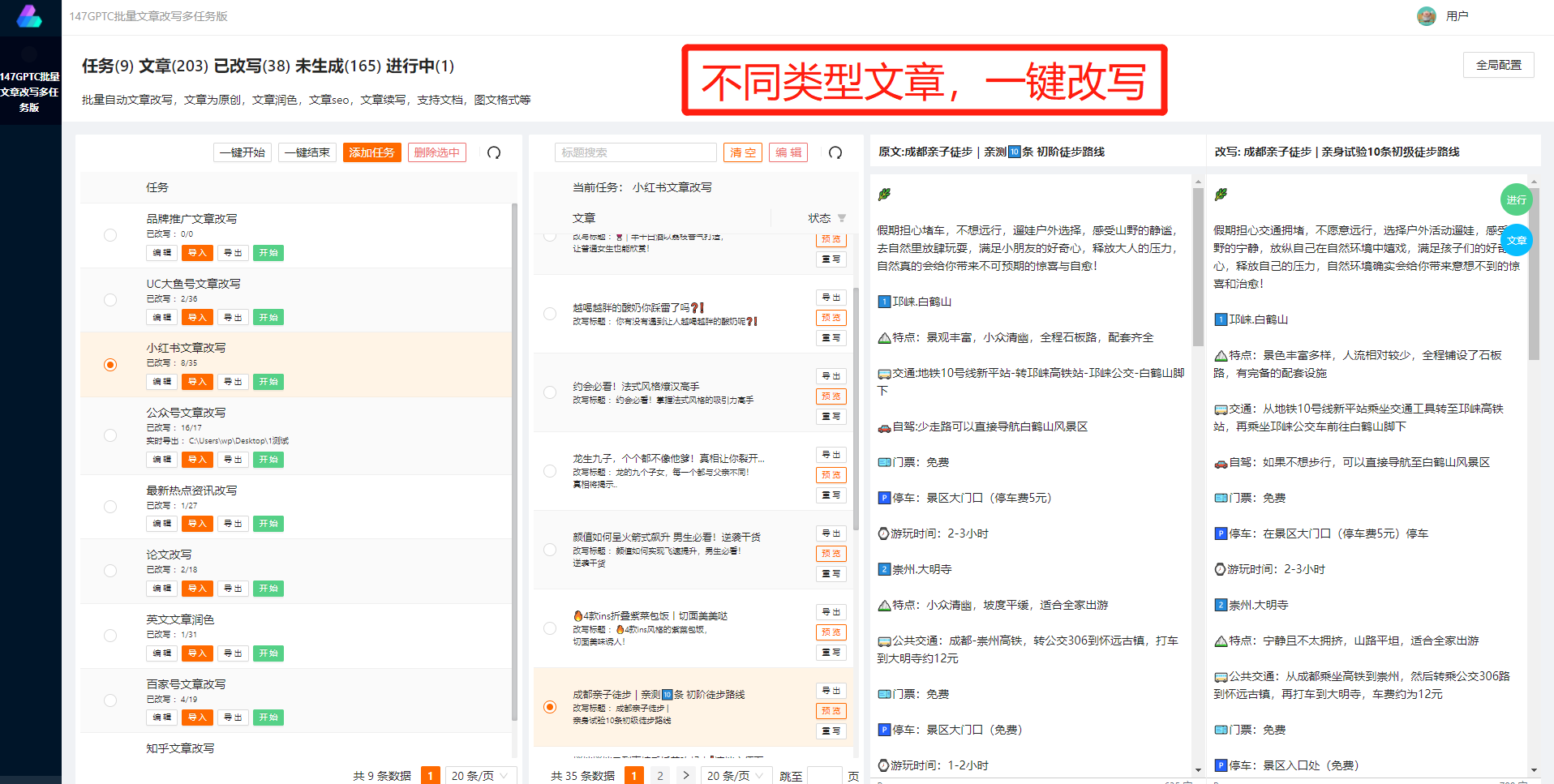
抓取數據的工具方法是指使用軟件工具來自動抓取互聯網上的數據。這些工具可以根據指定的條件和規則,在網頁上搜索相關數據,并以結構化的方式保存到數據庫或文件中。使用抓取數據的工具方法可以大大減輕人們的工作負擔,提高工作效率。
首先,要高效地使用抓取數據的工具方法,我們需要明確自己的需求。在準備使用工具方法之前,我們應該明確需要抓取哪些數據以及這些數據將如何被使用。明確需求可以幫助我們更加有針對性地設置抓取規則,避免抓取到無用數據,節省時間和ZY。
其次,我們需要選擇適合自己需求的抓取工具。市面上有很多抓取數據的工具,如Python中的BeautifulSoup、Scrapy等,Node.js中的Cheerio、Puppeteer等,以及專門的爬蟲框架。根據自己的實際情況和技術需求,選擇一個適合自己的抓取工具可以提高工作效率。
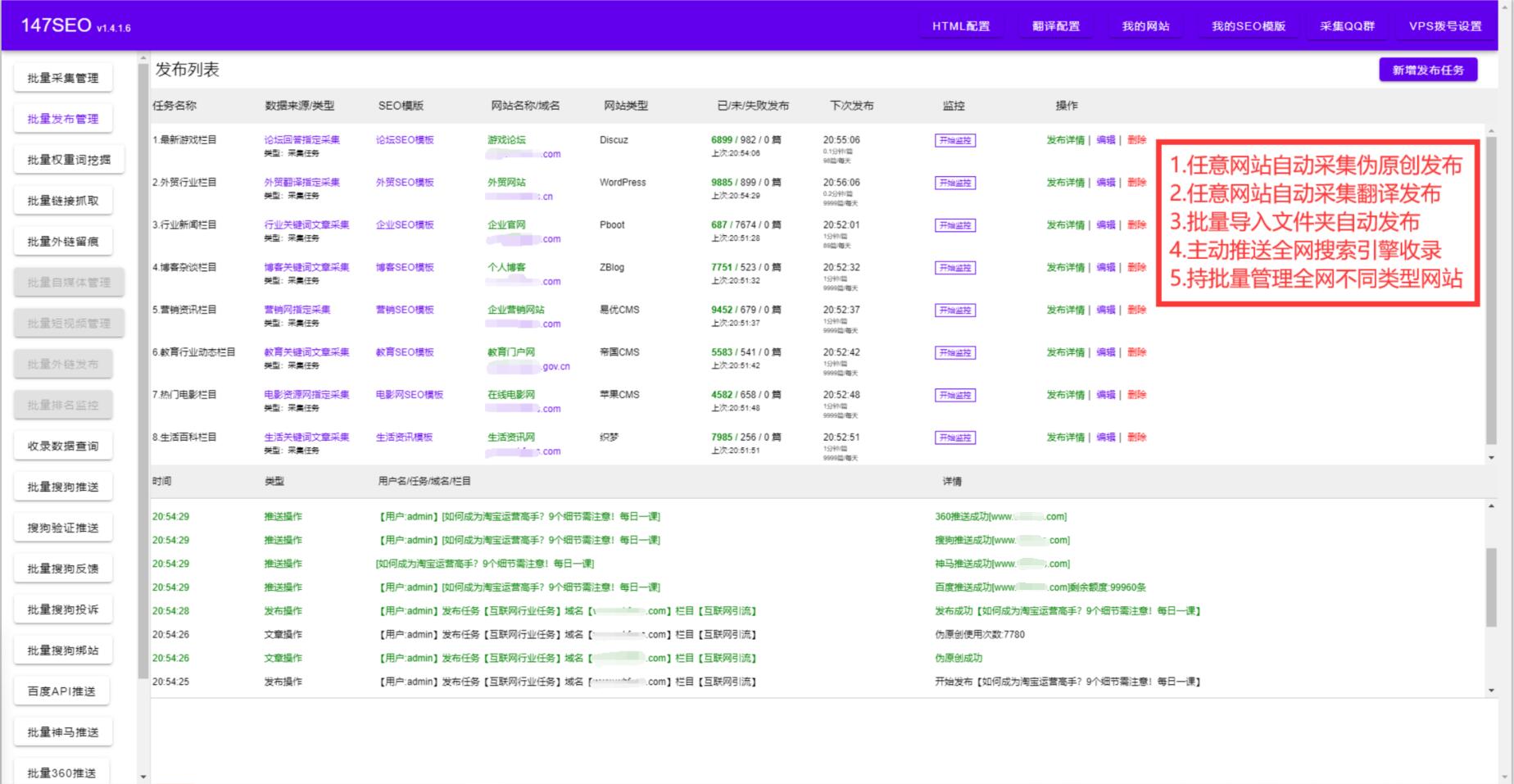
在設置抓取規則時,我們需要注意規則的靈活性和準確性。靈活的規則可以適應不同的網頁結構和變化,準確的規則可以抓取到我們需要的數據。通常,我們可以使用XPath、CSS選擇器等方式來定位和提取數據。同時,設置合適的抓取間隔和請求頻率可以避免對服務器造成過大負擔,提高工作效率。
抓取到數據后,我們需要進行數據處理和分析。首先,對抓取到的數據進行清洗和過濾,去除無用的信息和噪聲數據,提取出有用的部分。接著,進行數據的結構化和整理,使得數據易于使用和分析。最后,根據具體的需求,我們可以進行數據分析和建模,得到有價值的結論和見解。
總之,抓取數據的工具方法是一項強大的工具,可以幫助我們高效地處理和分析海量數據。通過明確需求、選擇合適的工具、設置靈活準確的抓取規則、進行數據處理和分析,我們能夠提高工作效率,發現數據背后的價值。希望本文能夠對讀者在抓取數據方面有所幫助,實現數據驅動的決策和創新。




