
作為信息爆炸時(shí)代的重要組成部分,新聞扮演著傳播信息、引導(dǎo)輿論的重要角色。如何高效獲取海量的新聞資訊,成為許多人關(guān)注的話題。而網(wǎng)絡(luò)爬蟲(chóng)技術(shù)的出現(xiàn),為我們提供了一種全新的解決方案。
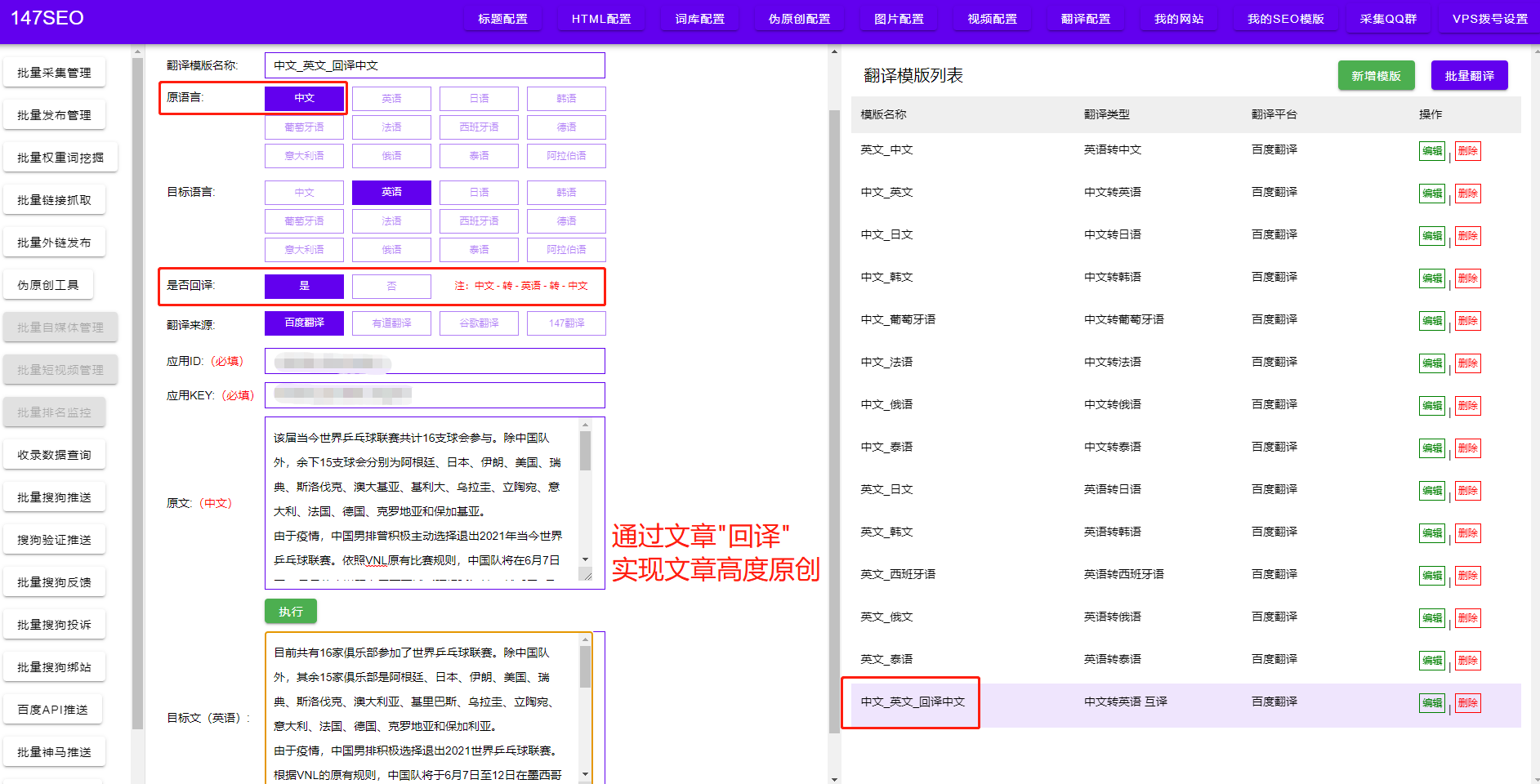
爬蟲(chóng)是一種自動(dòng)化程序,能夠模擬人的行為,自動(dòng)采集互聯(lián)網(wǎng)上的各種信息。爬蟲(chóng)在新聞?lì)I(lǐng)域應(yīng)用廣泛,通過(guò)爬蟲(chóng)技術(shù),我們可以輕松地爬取包括文字、圖片、shiping等多種形式的新聞數(shù)據(jù)。下面,我們將為你介紹如何使用爬蟲(chóng)來(lái)爬取新聞內(nèi)容。
一、確定爬蟲(chóng)目標(biāo) 在開(kāi)始爬取新聞之前,我們首先需要確定我們的爬蟲(chóng)目標(biāo)。要爬取的新聞網(wǎng)站有很多,我們可以選擇一些熱門(mén)的新聞網(wǎng)站作為目標(biāo),如新浪新聞、騰訊新聞等。根據(jù)自己的需求選擇合適的網(wǎng)站進(jìn)行爬取。
二、分析目標(biāo)網(wǎng)站的結(jié)構(gòu) 在進(jìn)行爬取之前,我們需要對(duì)目標(biāo)網(wǎng)站的結(jié)構(gòu)進(jìn)行分析。通過(guò)觀察網(wǎng)站的HTML源代碼,分析網(wǎng)頁(yè)的結(jié)構(gòu),確定需要爬取的數(shù)據(jù)在哪個(gè)位置。
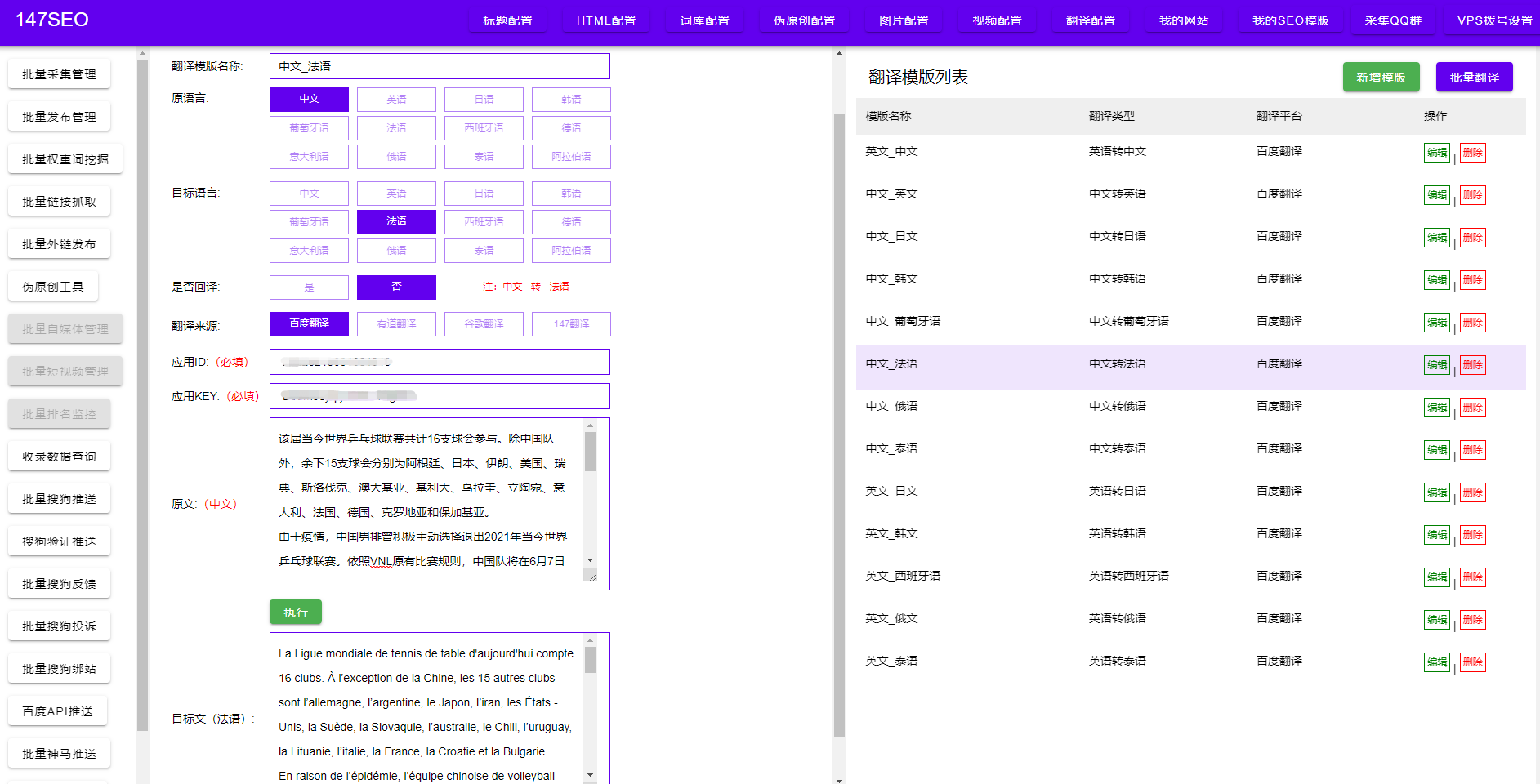
三、編寫(xiě)爬蟲(chóng)代碼 在分析目標(biāo)網(wǎng)站結(jié)構(gòu)之后,我們就可以開(kāi)始編寫(xiě)爬蟲(chóng)代碼了。使用Python語(yǔ)言編寫(xiě)爬蟲(chóng)代碼是最常見(jiàn)的選擇,Python提供了許多強(qiáng)大的爬蟲(chóng)框架和庫(kù),如Scrapy、BeautifulSoup等。根據(jù)自己的需求,選擇合適的工具,并按照其文檔進(jìn)行爬蟲(chóng)代碼的編寫(xiě)。
四、處理反爬措施 為了防止被網(wǎng)站屏蔽或封禁,我們需要在爬蟲(chóng)代碼中處理一些反爬措施。常見(jiàn)的反爬措施包括限制爬取速度、設(shè)置User-Agent、使用代理IP等。針對(duì)不同的反爬措施,我們需要做出相應(yīng)的處理,確保能夠正常獲取數(shù)據(jù)。
五、數(shù)據(jù)存儲(chǔ)與管理 爬取到的新聞數(shù)據(jù)需要進(jìn)行存儲(chǔ)和管理。我們可以選擇將數(shù)據(jù)存儲(chǔ)到數(shù)據(jù)庫(kù)中,如MySQL、MongoDB等,也可以存儲(chǔ)到本地文件中。另外,為了方便后續(xù)的數(shù)據(jù)分析和處理,我們還可以使用數(shù)據(jù)處理工具,如Pandas、NumPy等進(jìn)行數(shù)據(jù)清洗和分析。
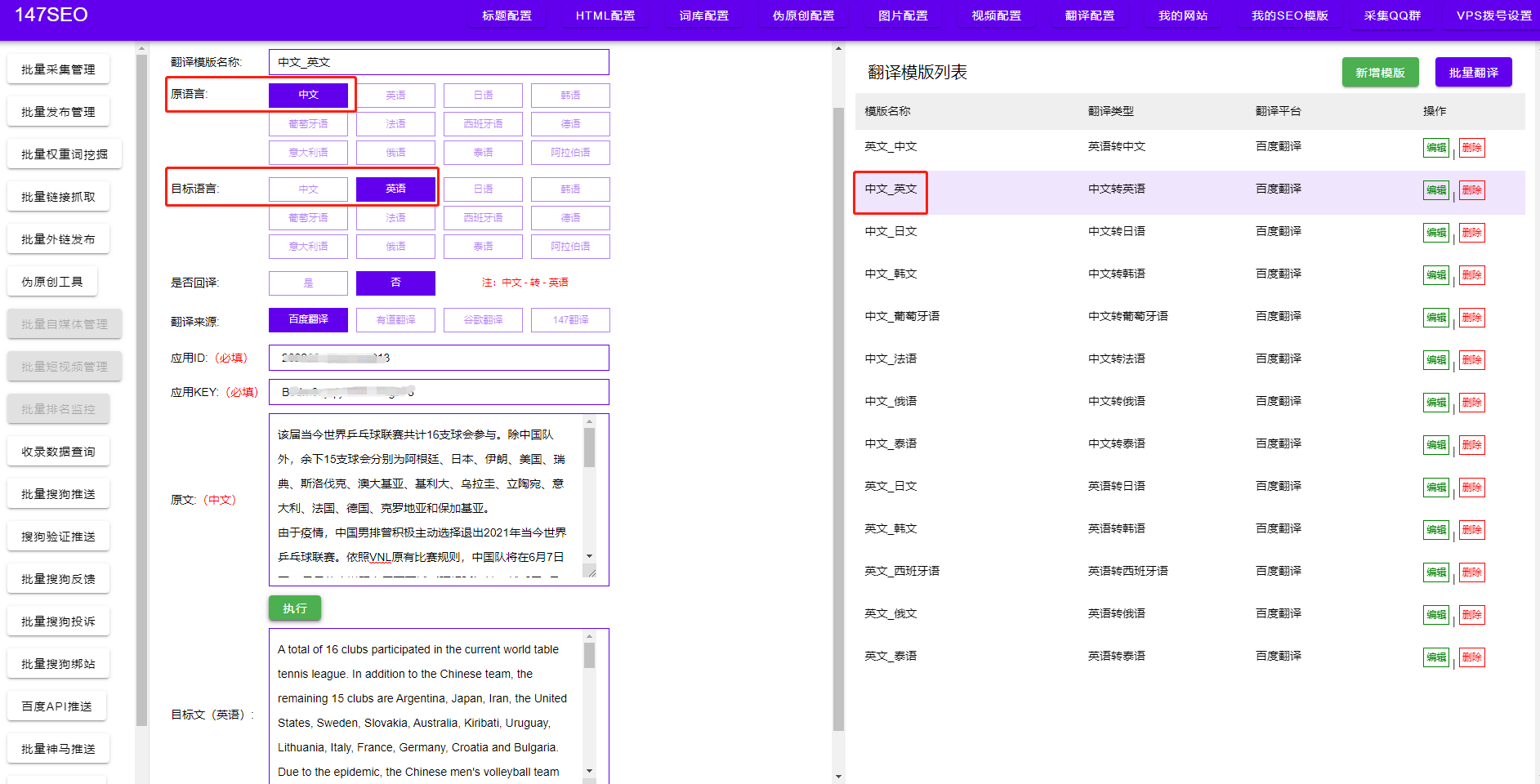
通過(guò)以上五個(gè)步驟,我們就可以使用爬蟲(chóng)技術(shù)來(lái)爬取新聞內(nèi)容了。通過(guò)靈活運(yùn)用爬蟲(chóng)技術(shù),我們不僅可以獲取到海量的新聞資訊,還可以進(jìn)行數(shù)據(jù)分析、挖掘和展示。采集到的新聞數(shù)據(jù)可以用于輿情監(jiān)測(cè)、新聞推薦等領(lǐng)域,為我們提供更多的信息和決策依據(jù)。
總結(jié)起來(lái),網(wǎng)絡(luò)爬蟲(chóng)技術(shù)在新聞爬取領(lǐng)域有著廣泛的應(yīng)用,通過(guò)爬蟲(chóng)技術(shù),我們可以輕松地獲取新聞網(wǎng)站上的新聞內(nèi)容。合理運(yùn)用爬蟲(chóng)技術(shù),我們可以更好地掌握信息,提高工作效率,為我們的工作和生活帶來(lái)便利。趕快動(dòng)手嘗試吧!



