
現代企業對于信息的獲取和處理變得日益重要。隨著互聯網的快速發展,網站抓取技術成為一種有力的工具,能夠實現對互聯網上海量數據的快速采集和分析。本文將介紹網站抓取的基本概念、應用場景以及使用網站抓取實現信息采集與數據分析的方法。
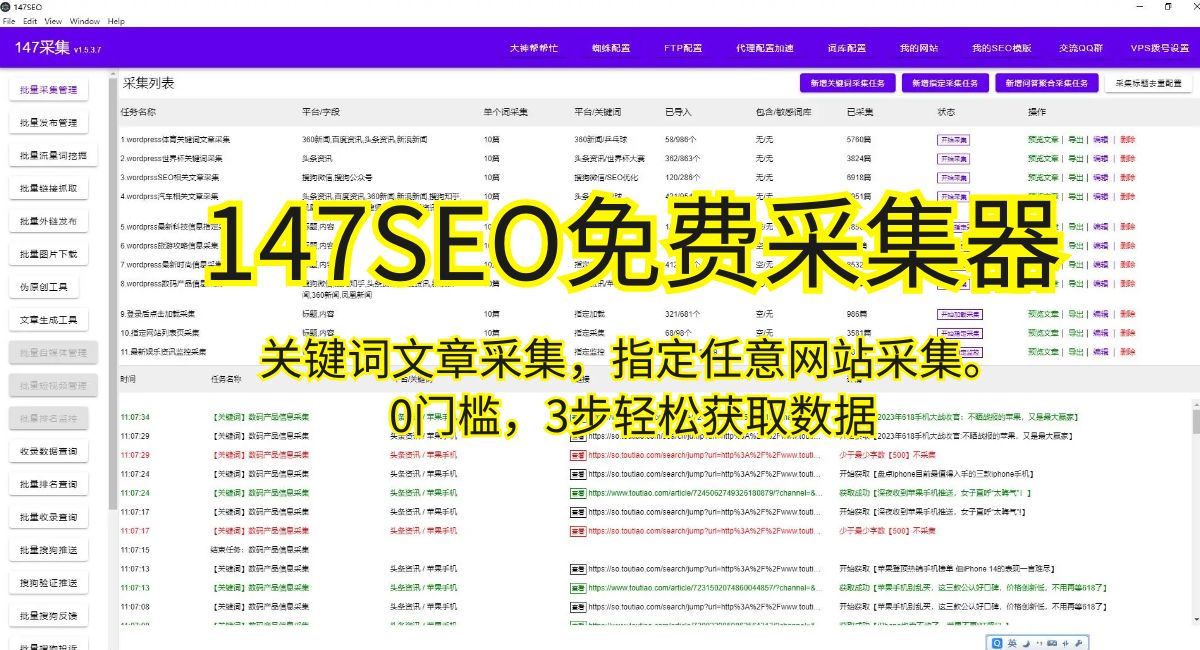
網站抓取,是指通過編寫程序模擬瀏覽器的行為,訪問特定的網頁,獲取所需的數據并進行處理的過程。它可以自動化地遍歷鏈接,采集大量信息,從而將海量數據轉化為有用的知識。網站抓取技術可以應用于多個領域,如輿情監測、競爭情報分析、商品價格比較等。通過對抓取的數據進行分析,企業可以獲取市場動態、競爭對手的信息,做出更加明智的決策。
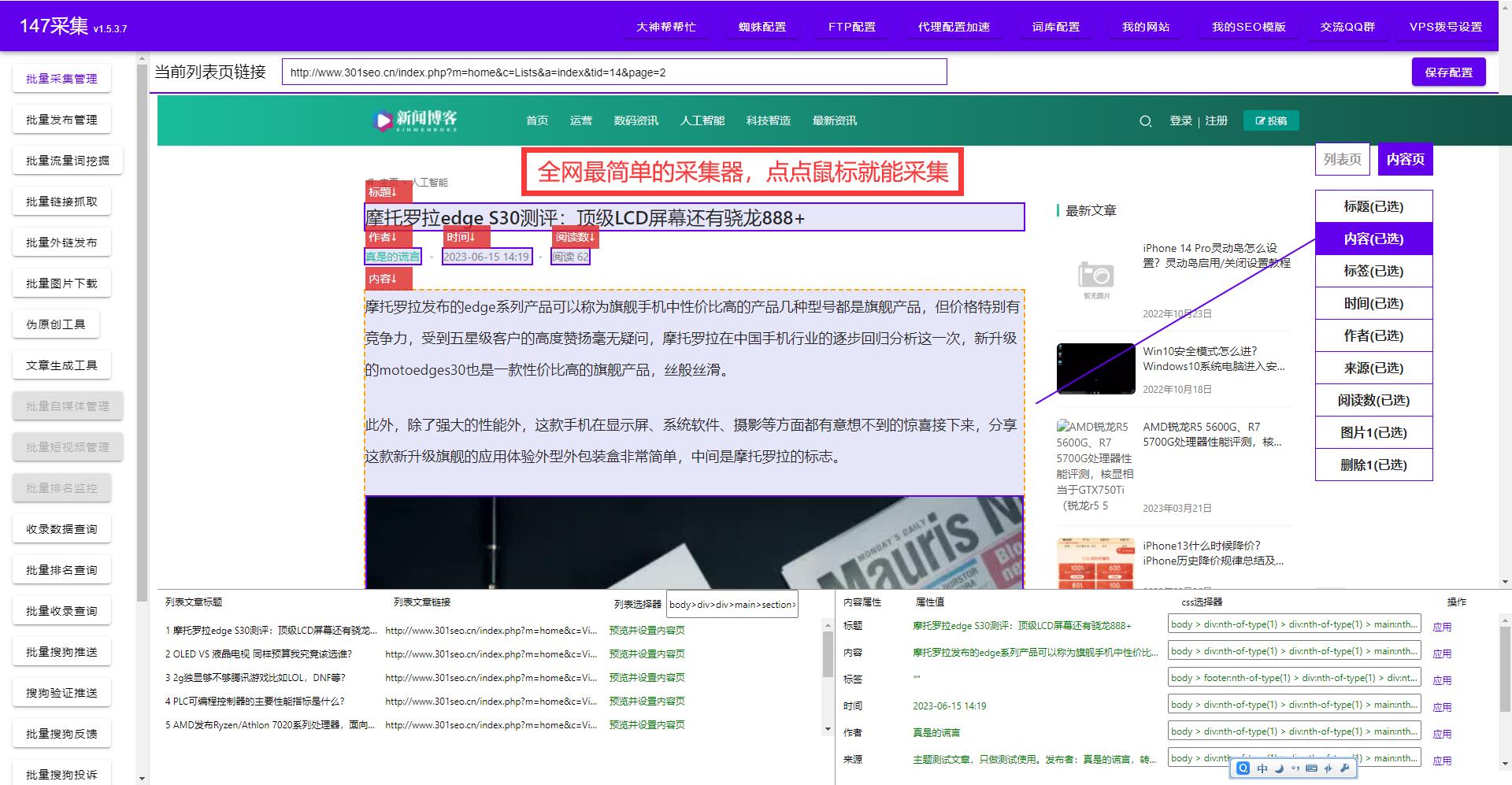
要使用網站抓取實現信息采集與數據分析,首先需要確定要抓取的網站和關鍵信息。然后,選擇合適的抓取工具和編程語言進行開發。常見的抓取工具包括Python的Scrapy、Java的Jsoup等。在開發過程中,需要注意處理反爬機制,以保證數據的完整性和準確性。
抓取數據后,下一步就是對數據進行處理和分析。可以使用各種數據分析工具,如Excel、Python的Pandas庫、R語言等。通過對數據進行清洗、篩選和統計,可以得到有用的結論和洞察。比如,在輿情監測中,可以通過抓取社交媒體上的用戶評論來了解消費者對某個品牌或產品的態度,以及競爭對手的市場表現等。
網站抓取技術的應用還有很多局限性和挑戰。首先,合法合規的問題。在進行網站抓取時,需要遵守規則法規和網站的使用協議,不得侵犯他人的合法權益。另外,網站抓取也面臨著反爬機制的挑戰。為了防止被抓取,網站可能會設置IP限制、驗證碼等,需要開發者做出相應的應對措施。
綜上所述,網站抓取是一種實現信息采集與數據分析的重要技術。通過使用網站抓取,企業可以快速獲取海量的數據,并通過數據分析得出有用的結論,為決策提供支持。然而,網站抓取也面臨著合法合規和反爬機制的挑戰,需要開發者高度關注。相信隨著技術的不斷發展和完善,網站抓取技術將在更多領域得到廣泛應用。



