
在當今信息爆炸的時代,網站數據成為了企業和個人獲取價值的重要來源。而要獲取準確、全面的數據就需要大量的時間和人力投入,這無疑給數據分析師和營銷人員帶來了巨大的負擔。那么如何利用爬蟲技術提升網站數據收集效率呢?
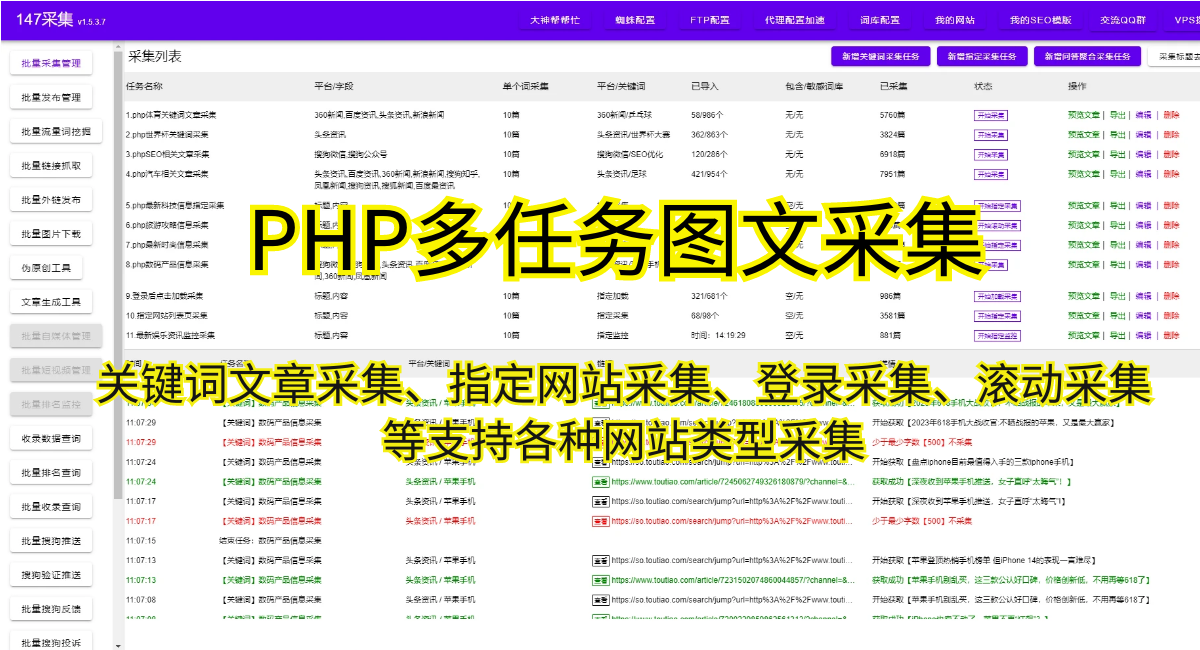
爬蟲技術,顧名思義,即通過編寫程序模擬人類瀏覽行為,自動獲取網頁上的數據。它可以快速地爬取互聯網上的大量數據,并進行結構化處理,極大地提高了數據收集效率。下面,我們將以一個實際案例,介紹如何利用爬蟲技術爬取一個網站的數據。
首先,我們需要選擇合適的爬蟲工具。市面上有很多爬蟲工具可供選擇,例如Python的Scrapy框架、Node.js的Puppeteer等。根據實際需求和技術儲備,選擇合適的工具非常重要。
接下來,我們需要了解目標網站的結構和數據特點,這樣才能更好地編寫爬蟲程序。通常可以通過查看網頁源碼、分析API接口、使用開發者工具等方法來獲取相關信息。這些信息包括網頁的URL結構、數據所在節點的唯一標識、數據格式等等。
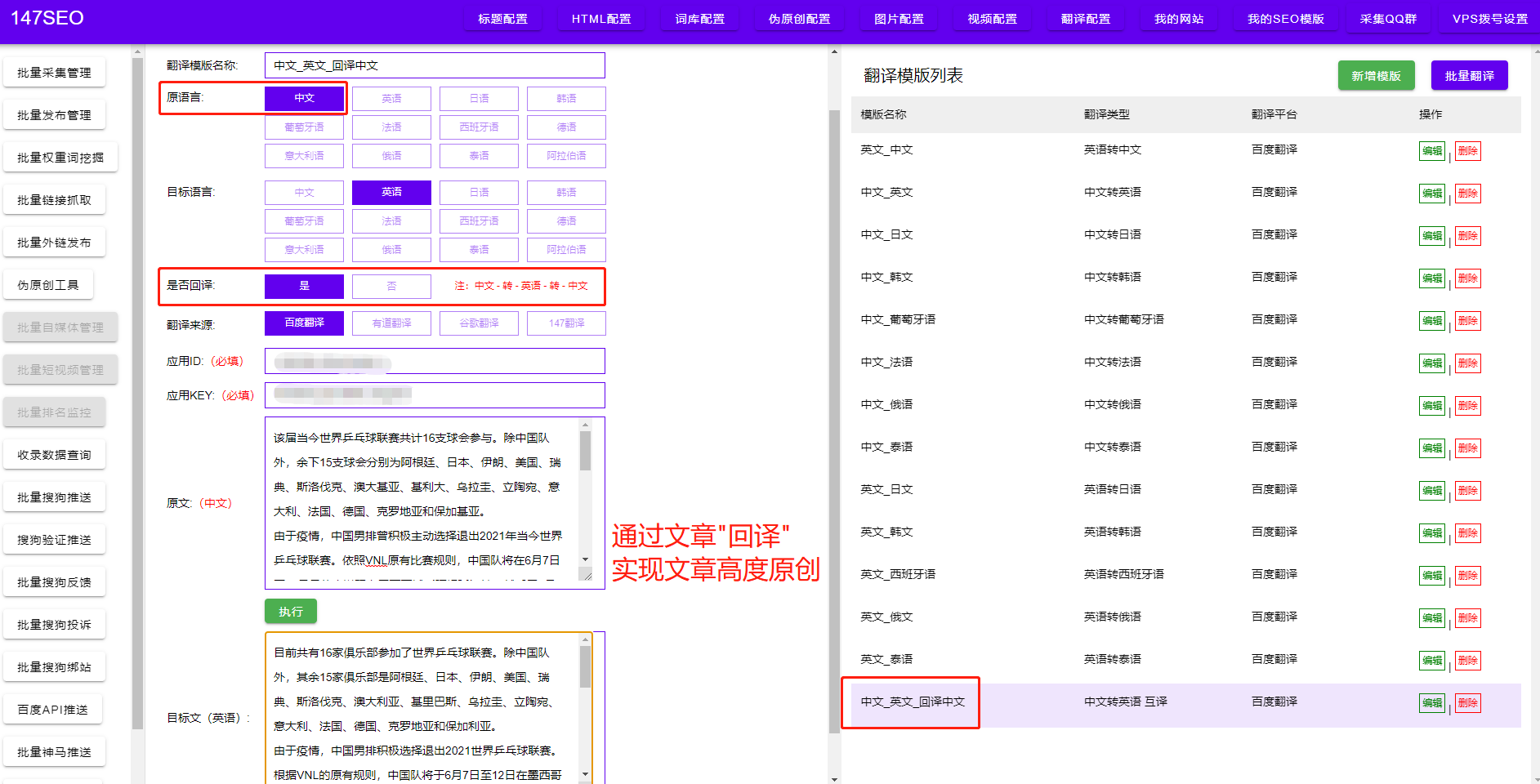
一旦我們了解了目標網站的結構,就可以開始編寫爬蟲程序了。首先,我們需要發送HTTP請求,獲取網頁的HTML代碼。然后,通過使用XPath、CSS選擇器等方式,定位到目標數據所在的節點,并提取出需要的數據。最后,我們可以將提取到的數據保存到本地文件或數據庫中,以備后續分析和使用。
當爬蟲程序編寫完成后,我們需要進行測試和調試。通過模擬多種情況下的爬取操作,確保程序能夠穩定運行并正確提取數據。同時,我們需要遵守網站的爬蟲規則,不要給目標網站造成過大的訪問負擔,避免觸發反爬蟲機制。
除了基本的爬蟲技術外,還可以利用一些高級技巧來提升數據收集的效率。例如,使用多線程或異步請求來并發地獲取數據,減少爬取時間;使用代理服務器來隱藏自己的真實IP地址,防止被封禁;使用反反爬蟲技術來繞過一些常見的反爬蟲手段等等。當然,這些技巧需要根據具體情況來選擇和使用。
總之,利用爬蟲技術可以大大提升網站數據收集的效率和準確性。但是,我們在使用爬蟲技術時也要遵守相關的規則法規和道德規范,不要濫用數據和侵犯他人的權益。只有正確合法地使用爬蟲技術,才能充分發揮其價值,為企業和個人帶來更多的益處。



