市面上很多免費(fèi)的采集軟件���,實(shí)際都是收費(fèi)的���,免費(fèi)的采集實(shí)際很少���,很多軟件都是打著免費(fèi)的名義���,其實(shí)都是要收費(fèi)的。
免費(fèi)的采集軟件性價(jià)又高的軟件少之又少���。
我們?cè)谌粘9ぷ骱蛯W(xué)習(xí)中���,對(duì)一些有價(jià)值的文章進(jìn)行采集可以幫助我們提高對(duì)信息的利用率和整合率,對(duì)于新聞、各大行業(yè)等類型的電子文章���,我們可以采用工具進(jìn)行采集���。
為什么要使用采集:
人的趨利性和懶惰性是造成文章采集這個(gè)問(wèn)題爭(zhēng)議性如此大的主要原因。對(duì)于很多大網(wǎng)站而言���,權(quán)重比例非常高而且網(wǎng)站中的很多idea,數(shù)據(jù)量都高達(dá)幾百萬(wàn)���。就算是一個(gè)編輯���,一天能寫(xiě)10篇原創(chuàng)內(nèi)容���,一年也只能生產(chǎn)3650篇文章���。要想達(dá)到100萬(wàn)的數(shù)據(jù)量���,要整整寫(xiě)270多年才能達(dá)到這個(gè)數(shù)字���,這數(shù)字非?��?膳?��,對(duì)人工而言根本不現(xiàn)實(shí)���。之所以有如此多的人進(jìn)行文章采集���,很大一部分原因都是因?yàn)檫@個(gè)���。從另外一個(gè)角度講���,展開(kāi)人工采集���,能夠?yàn)榫W(wǎng)站帶來(lái)更多的流量���,從而造成網(wǎng)站更大的知名度���。
置.png")
什么樣的采集軟件才算好用:
1���、智能傻瓜式的采集���,無(wú)需配置規(guī)則���,輸入關(guān)鍵詞即可實(shí)現(xiàn)采集; 可從主流媒體平臺(tái)獲取文章素材���,確保文章內(nèi)容多樣性?
2���、采集源整合了各大主流數(shù)據(jù)平臺(tái)以及垂直平臺(tái)���,全方位收集文章庫(kù)���, 滿足各個(gè)行業(yè)客戶需求
3���、無(wú)論是采集穩(wěn)定性或是采集效率���,都能夠滿足個(gè)人���、團(tuán)隊(duì)和企業(yè)級(jí)采集需求���。
4���、在文章原創(chuàng)時(shí)自動(dòng)鎖定品牌詞���、產(chǎn)品詞���,提升文章可閱讀性及核心詞不會(huì)被原創(chuàng)?
選擇什么樣的采集

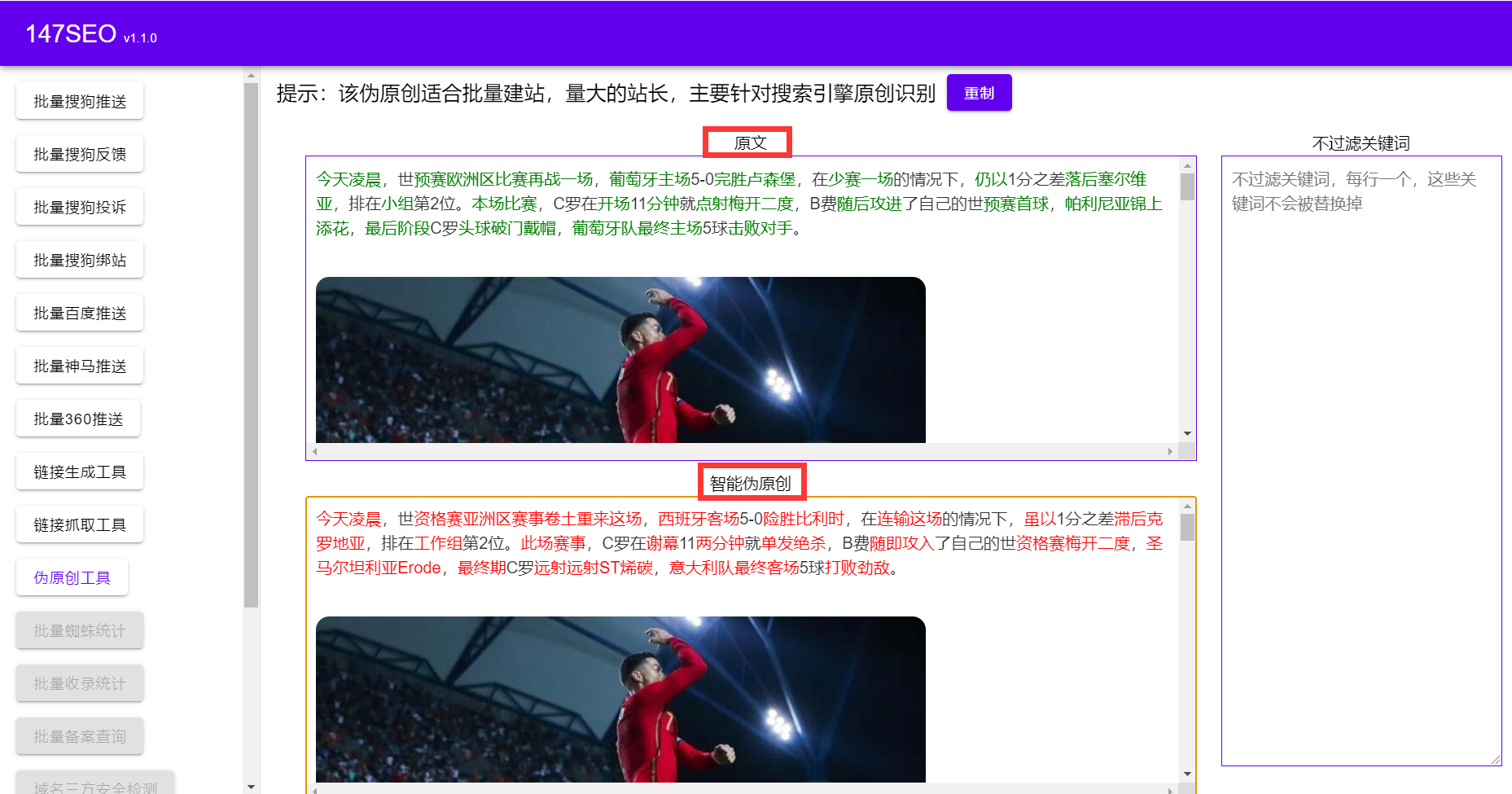
采集的文章需要偽原創(chuàng)嗎���?
需要?��。���?��!偽原創(chuàng)是指把一篇原創(chuàng)采集過(guò)來(lái)的文章進(jìn)行再加工���,使其讓搜索引擎認(rèn)為是一篇原創(chuàng)文章���,從而提高網(wǎng)站權(quán)重 ���。利于網(wǎng)站收錄
目前seo的重點(diǎn)在于內(nèi)容���,內(nèi)容為王的道理做SEO都知道。原則上高質(zhì)量的原創(chuàng)文章對(duì)于網(wǎng)站優(yōu)化來(lái)說(shuō)���,效果是最好的,但是原創(chuàng)文章的難度太大,很多網(wǎng)站不可能都保持原創(chuàng)���,所以更多的時(shí)候是采用偽原創(chuàng)。
對(duì)于seo來(lái)說(shuō)���,是否是seo原創(chuàng)文章,不是根據(jù)讀者閱讀后的感受來(lái)評(píng)判���,而是根據(jù)搜索引擎的判斷來(lái)進(jìn)行區(qū)分是否是SEO原創(chuàng)文章。一般來(lái)說(shuō)���, 搜索引擎會(huì)對(duì)于新文章和自己的已經(jīng)收錄的進(jìn)行比較,通過(guò)篩選關(guān)鍵詞或者句子來(lái)判斷是否為原創(chuàng)���,如果兩篇文章相似度過(guò)高,那么將會(huì)判定該文章為抄襲���,將不會(huì)收錄!���!