
數據爬取的主要步驟
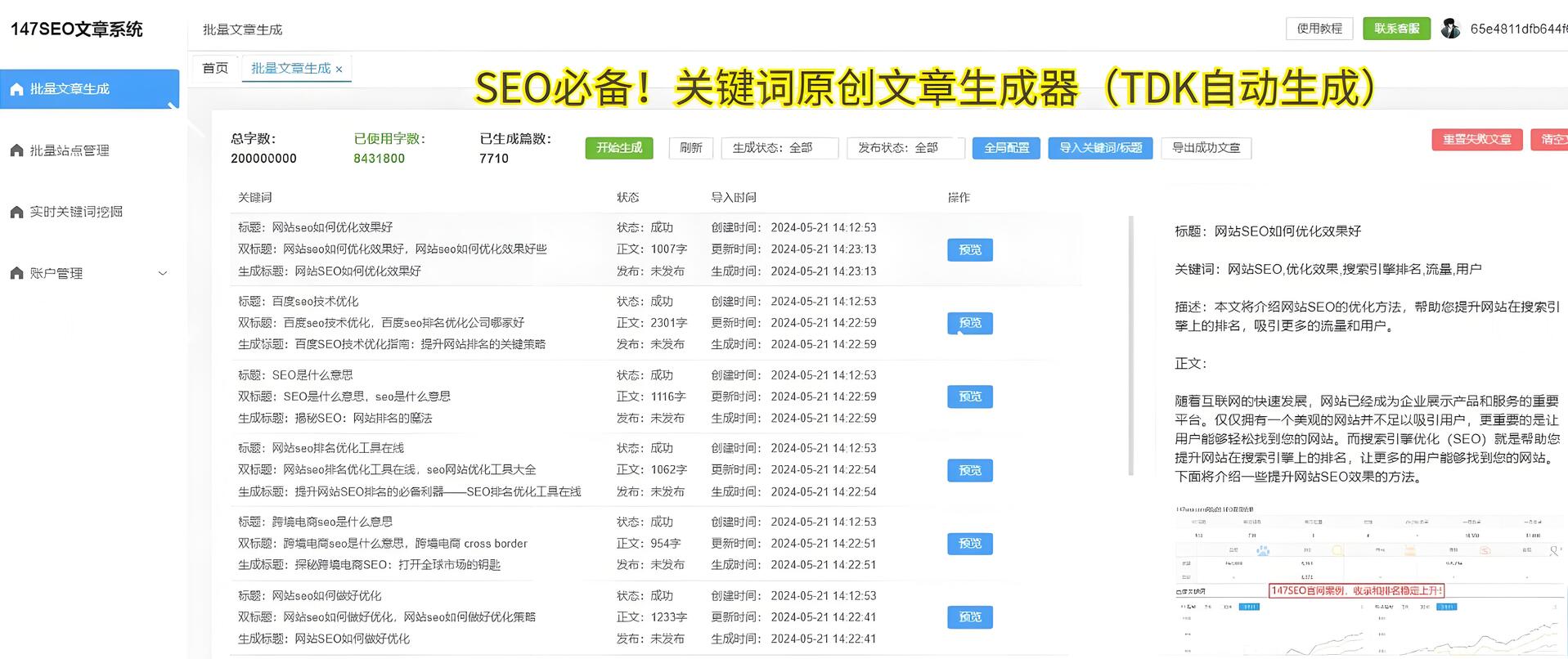
數據在當前的信息時代非常重要,通過數據分析和挖掘,可以為人們提供準確、有用的信息,支持決策和創新。然而,在大數據時代,如何高效、準確地獲取所需的數據成為一個關鍵的問題。數據爬取(WebScraping)技術應運而生,它允許我們從網頁上自動化地提取數據并存儲到本地。本文將詳細介紹數據爬取的主要步驟,幫助讀者了解網絡爬蟲的工作原理和實踐技巧。
1.確定爬取目標 在開始數據爬取之前,首先需要明確爬取的目標。確定要爬取的網站、頁面和數據類型是非常重要的。根據爬取目標的不同,我們可以選擇不同的爬取工具和技術。
2.分析目標網頁 在確定爬取目標之后,我們需要對目標網頁進行分析。了解網頁的結構和布局,找出所需數據所在的位置。通常,我們可以通過查看網頁源代碼或使用開發者工具來分析網頁結構。
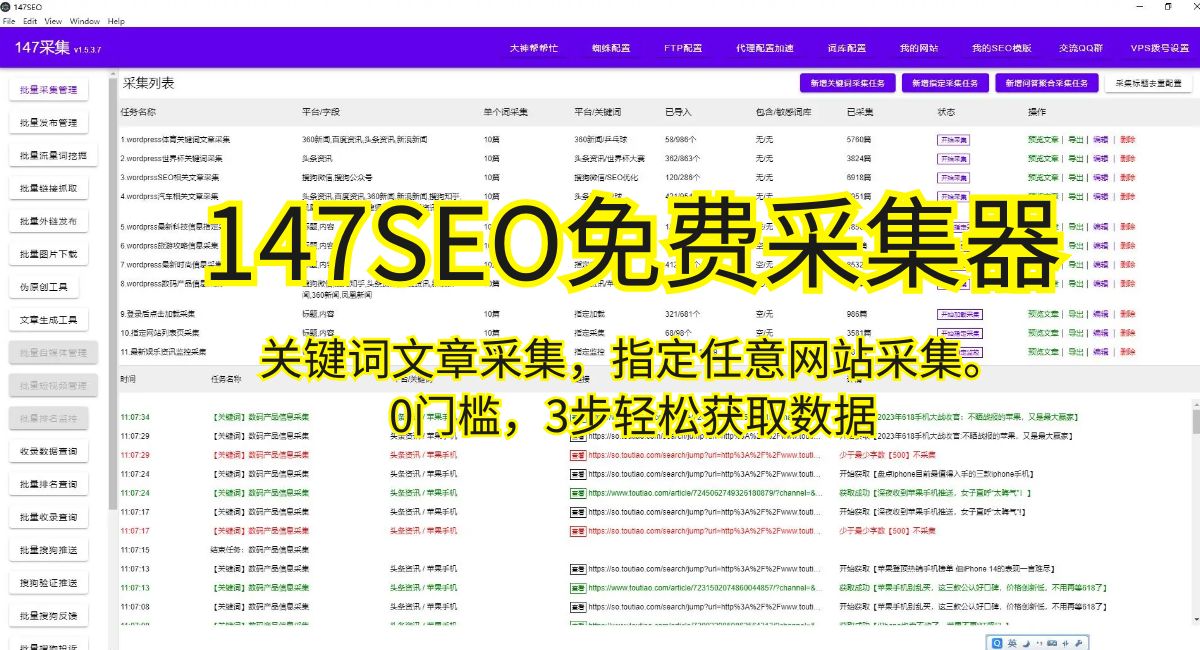
3.編寫爬蟲程序 在分析目標網頁之后,我們可以開始編寫爬蟲程序。根據目標網頁的結構和布局,選擇合適的編程語言和爬蟲框架來實現爬蟲程序。常用的編程語言包括Python、Java和JavaScript,常用的爬蟲框架包括Scrapy、BeautifulSoup和Selenium。
4.發送HTTP請求 編寫好爬蟲程序之后,我們需要通過發送HTTP請求來獲取目標網頁的內容。根據網頁的不同,我們可以使用GET請求或POST請求,同時也需要設置合適的請求頭信息。
5.解析網頁內容 獲取到網頁的內容之后,我們需要對網頁進行解析。根據目標數據所在的位置和網頁的結構,我們可以使用正則表達式、XPath或CSS選擇器等方法來提取數據。

6.數據處理和存儲 在完成數據解析之后,我們需要對提取到的數據進行處理和存儲。可以對數據進行清洗、去重、轉換等操作,以適應后續的分析和應用需求。同時,我們也可以選擇將數據存儲到數據庫、Excel或其他數據文件中。
7.設置爬蟲定時任務 如果需要定期自動化地進行數據爬取,我們可以設置爬蟲定時任務。通過使用定時任務工具,如crontab或Windows任務計劃器,我們可以按照設定的時間間隔執行爬蟲程序。
總結 數據爬取作為一種重要的數據獲取和處理技術,在各個領域都有著廣泛應用。通過了解數據爬取的主要步驟,我們可以更加有效地獲取所需的數據,并為后續的數據分析和挖掘工作提供支持。希望本文可以幫助讀者了解網絡爬蟲的工作原理和實踐技巧,并在實際應用中取得好的結果。



