
隨著信息科技的不斷發(fā)展,我們的世界已經(jīng)成為了一個信息大爆炸的時代。我們每天都在接受著來自各個方面的新聞、資訊和數(shù)據(jù),這些信息既有好消息,也有壞消息。無論是個人還是公司組織,都需要善于獲取和處理信息才能夠在競爭激烈的市場中立于不敗之地。
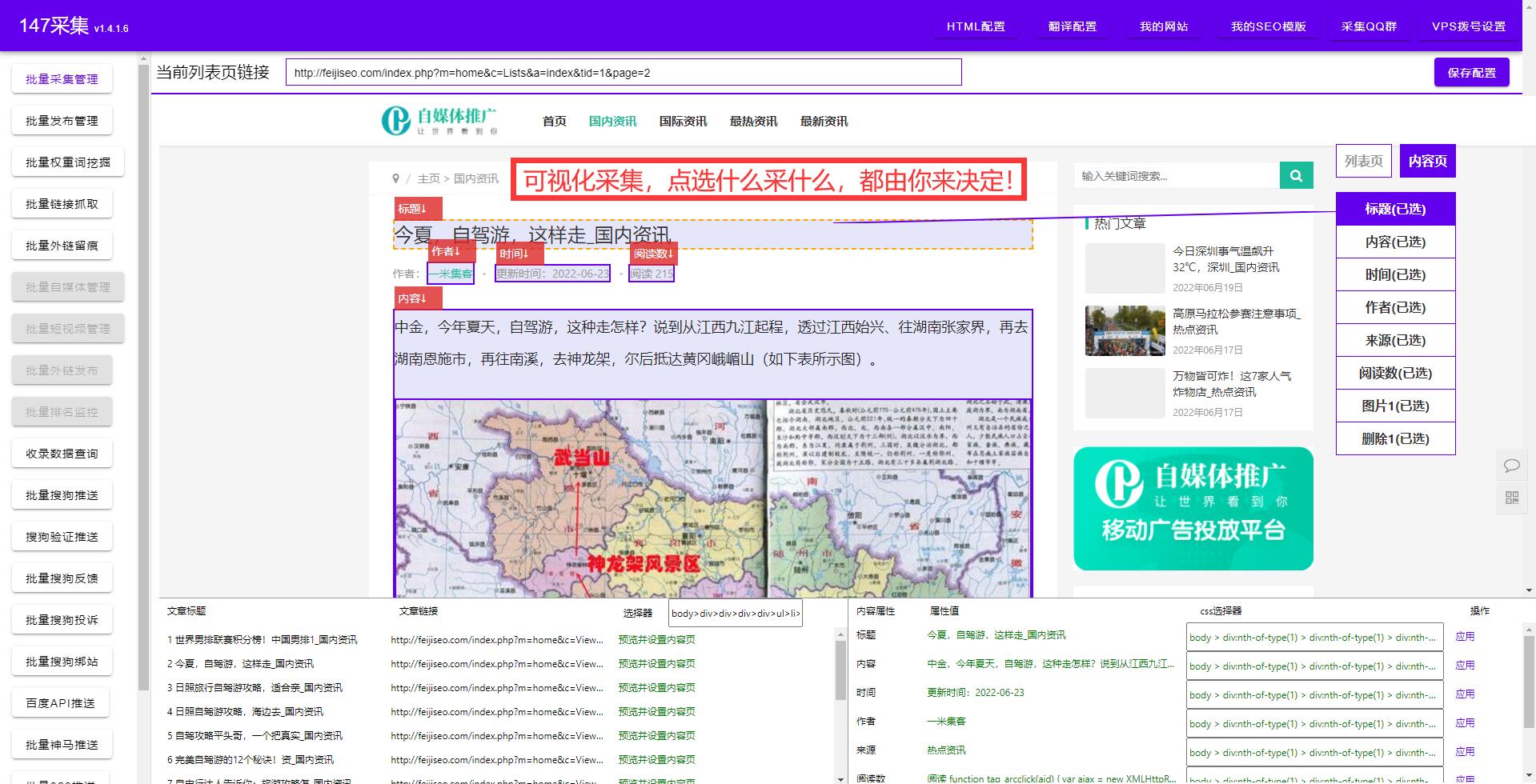
而獲取信息,特別是新聞信息,是我們在競爭中常常面臨的問題。即使是通過搜索引擎,獲取到的也只是數(shù)量繁多、質(zhì)量參差不齊的信息。那么,如何才能更加高效、快速地獲取到我們所需要的新聞信息呢?
答案就是通過文章標(biāo)題采集來實現(xiàn)。
文章標(biāo)題采集是什么?
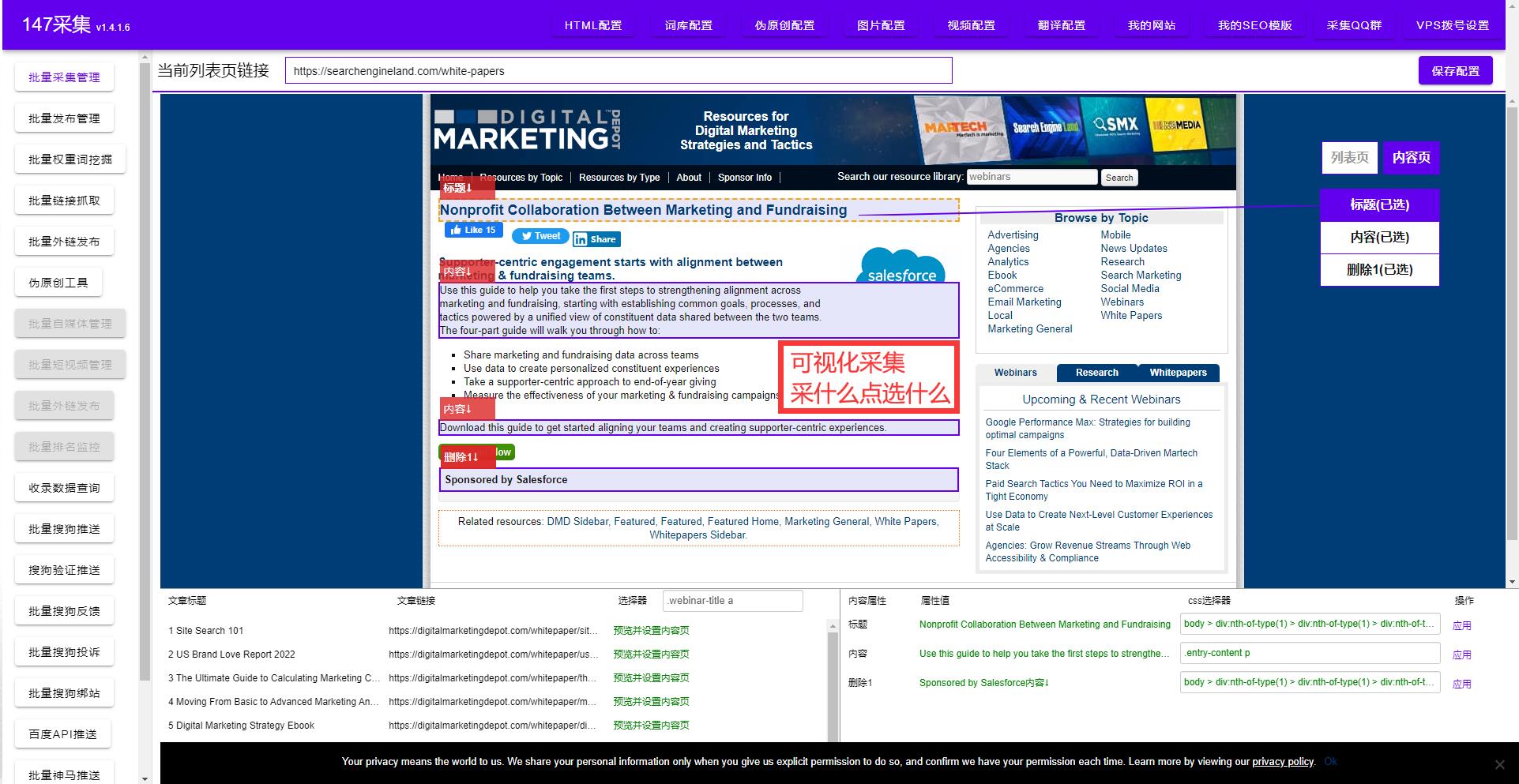
文章標(biāo)題采集,顧名思義,就是通過網(wǎng)絡(luò)爬蟲等技術(shù)手段,采集新聞資訊的標(biāo)題,從標(biāo)題中獲取新聞的摘要信息,比如發(fā)布時間和來源等,以及新聞的鏈接地址,進而獲取新聞詳細(xì)內(nèi)容的技術(shù)手段。通過文章標(biāo)題采集,我們可以非常快速和高效地獲取一定范圍內(nèi)的新聞信息。
如何進行文章標(biāo)題采集?
文章標(biāo)題采集的技術(shù)要求相對較高,需要一定的編程技能以及網(wǎng)絡(luò)技術(shù)。同時,也需要有一定的爬蟲經(jīng)驗和對目標(biāo)網(wǎng)站數(shù)據(jù)源的了解。
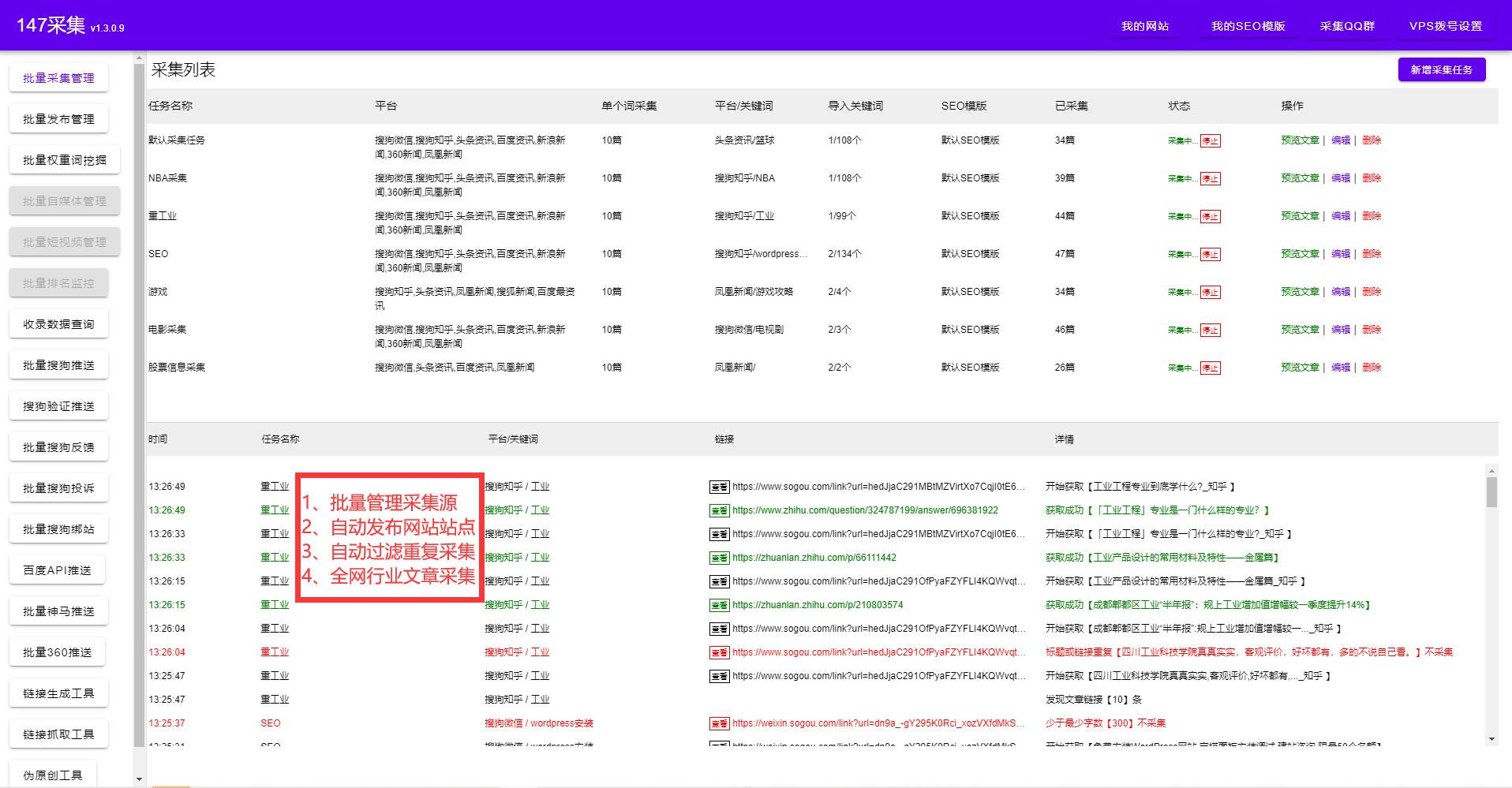
一般來說,文章標(biāo)題采集的過程包括以下幾個步驟:
1.確定數(shù)據(jù)源
首先需要確定需要采集的新聞來源,比如政府網(wǎng)站、新聞網(wǎng)站等。在互聯(lián)網(wǎng)上,有很多開發(fā)者提供了常用數(shù)據(jù)源和對應(yīng)的 API 接口,我們可以先嘗試直接使用這些數(shù)據(jù)源
2.編寫爬蟲程序
編寫爬蟲的核心就是使用各種編程工具,模擬人類點擊、提交表單等操作,獲取數(shù)據(jù)源上的新聞以及對應(yīng)的詳細(xì)信息。
3.篩選和提取新聞標(biāo)題和摘要
通過程序?qū)⒆ト〉降男侣剺?biāo)題以及摘要篩選和提取出來。可以采用相應(yīng)的程序庫來進行自然語言處理,對標(biāo)題和摘要數(shù)據(jù)進行清洗和處理。
4.保存數(shù)據(jù)
將抓取到的新聞數(shù)據(jù)保存到相應(yīng)的數(shù)據(jù)源中。
文章標(biāo)題采集的優(yōu)勢是什么?
相對于傳統(tǒng)的新聞搜索方式,在文章標(biāo)題采集方面具有以下優(yōu)勢:
1.大規(guī)模獲取,提高效率
文章標(biāo)題采集可以快速獲取大量新聞標(biāo)題和摘要,從而快速篩選搜集所需信息,提高新聞信息收集效率。
2.自動化操作,減少工作量
通過編寫程序,可以實現(xiàn)自動化操作,減少人工工作量,提高新聞信息篩選的準(zhǔn)確度和效率。
3.獲取更全面的新聞信息
傳統(tǒng)的搜索方式,會優(yōu)先自然搜索結(jié)果而對搜索引擎的廣告進行過濾,文章標(biāo)題采集可以直接獲取當(dāng)日的新聞信息,可以更全面地了解當(dāng)日的新聞要點。
結(jié)語:
文章標(biāo)題采集技術(shù)的應(yīng)用,可以為我們獲取新聞信息提供更加快速和高效的方式,并且能夠提高我們對信息的掌握能力。同時也讓我們在信息時代中走得更遠、看得更廣,更好地把握商業(yè)上的機會。



