
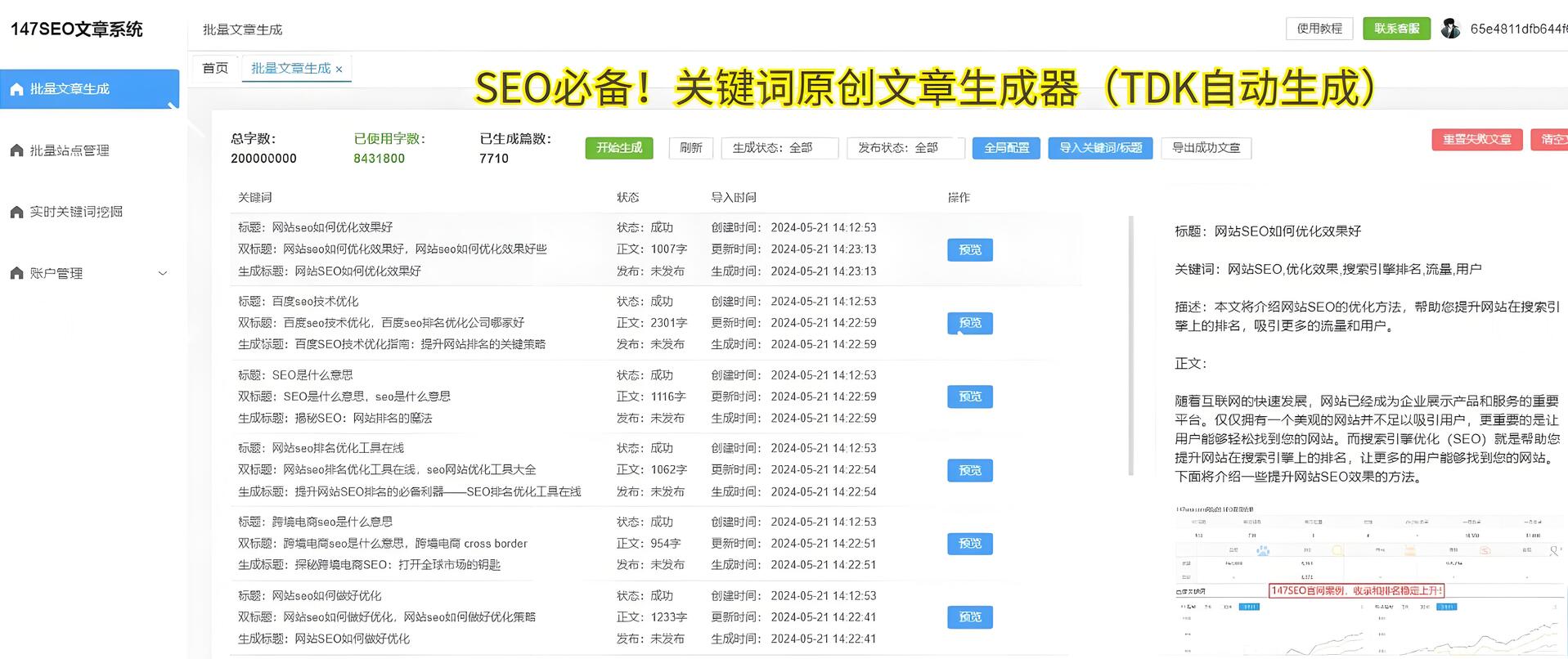
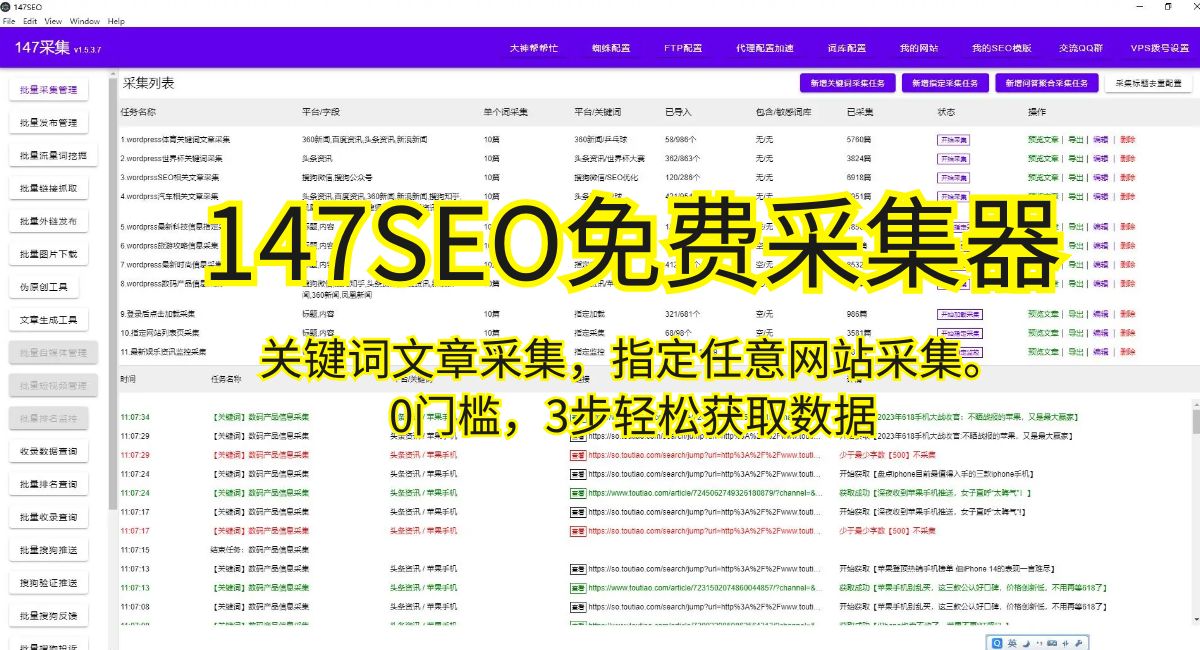
在使用小旋風蜘蛛池進行數據采集時,我們有時會遇到無法進行采集的情況。這個問題可能會給我們的工作帶來一些困擾。我們將探討一些導致小旋風蜘蛛池無法進行采集的原因,并提供一些解決方案。
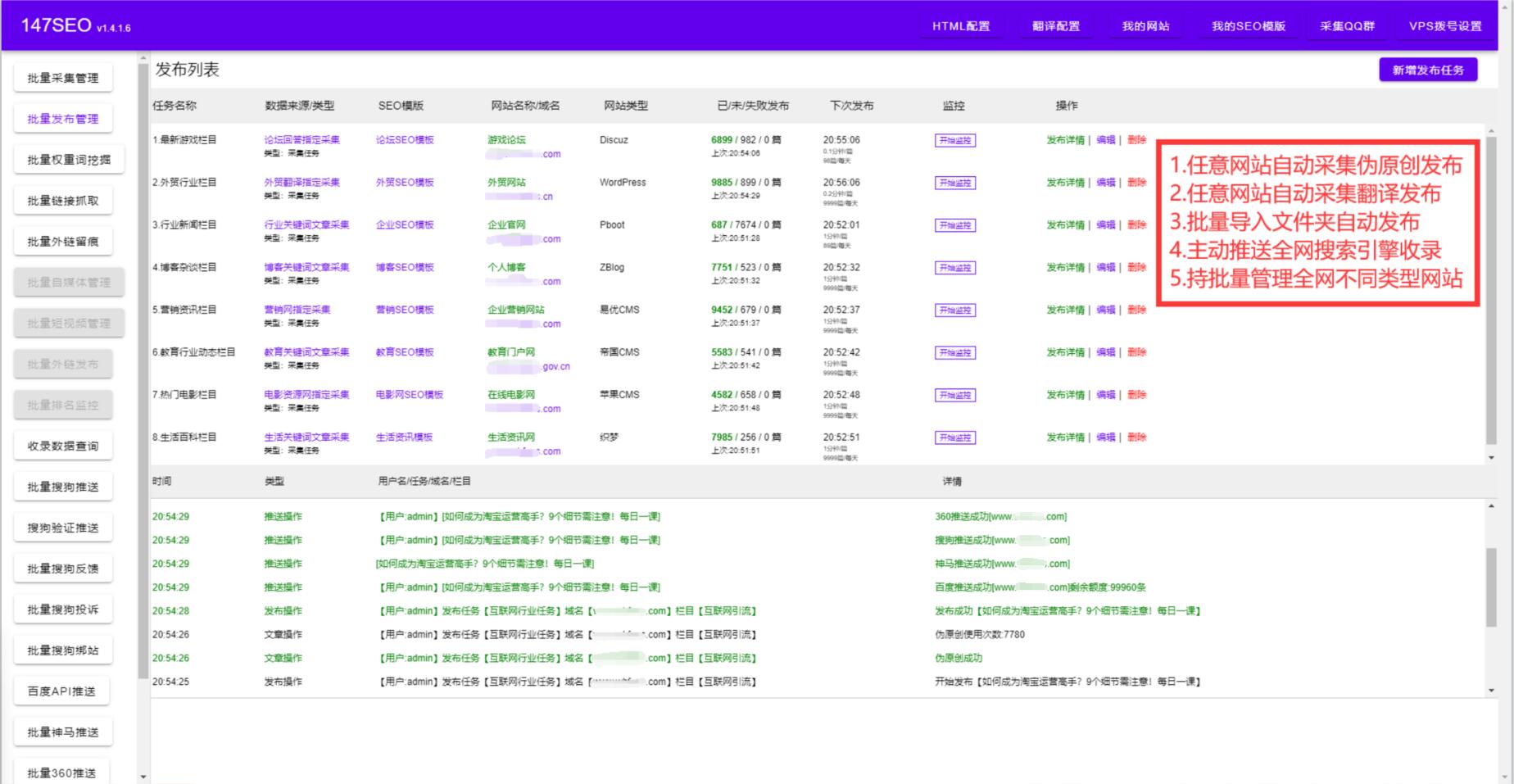
一、服務器反爬機制: 有些網站在服務器端設置了反爬機制,以防止爬蟲程序進行數據采集。這些反爬機制包括IP封禁、驗證碼和訪問頻率限制等。當小旋風蜘蛛池被服務器檢測到是爬蟲程序時,就會被阻止進行采集。解決方案是使用代理IP、自動打碼或設置訪問延時等手段,來規避這些反爬機制。
二、頁面渲染問題: 有些網站的頁面是通過JavaScript動態生成的,而小旋風蜘蛛池默認只會采集靜態頁面。這導致小旋風蜘蛛池無法正確解析頁面,無法獲取所需的數據。解決方案是使用PhantomJS等瀏覽器自動化工具來模擬真實瀏覽器環境,從而實現對動態頁面的采集。
三、登錄問題: 一些網站需要進行登錄才能獲取數據,而小旋風蜘蛛池默認是未登錄狀態。當嘗試采集需要登錄的網站時,小旋風蜘蛛池無法獲取所需數據。解決方案是使用小旋風蜘蛛池提供的登錄功能,并提供正確的登錄信息,以獲取登錄后的數據。
四、網站結構變動: 有些網站可能會不定期地調整頁面結構或URL地址,這導致小旋風蜘蛛池無法正確解析頁面或無法找到目標網頁。解決方案是定期對目標網站進行監測,如果發現頁面結構或URL發生變化,及時進行相應的調整和更新。
五、采集規則設置問題: 小旋風蜘蛛池的采集規則設置對于數據采集非常重要。如果設置不當,就會導致無法采集到目標數據。解決方案是根據網站的具體情況,合理設置采集規則,確保規則能夠準確匹配目標數據。
除了以上列舉的問題和解決方案,還有一些個別網站可能會采用更復雜的反爬機制,這需要根據具體情況進行針對性的解決。了解導致小旋風蜘蛛池無法進行采集的原因,并采取相應的解決方案,將能夠提高采集效率和質量,更好地完成數據采集的任務。
147SEO » 小旋風蜘蛛池無法進行采集的原因及解決方案



