
解鎖動態網頁數據的新技能,輕松爬取你想要的信息
隨著互聯網的發展,動態網頁越來越普遍,這為用戶獲取信息帶來了便利,但同時也給數據爬取帶來了一定的困難。傳統的爬蟲技術往往無法有效地獲取動態網頁上的數據,我們需要一種新的技能來解決這個問題。
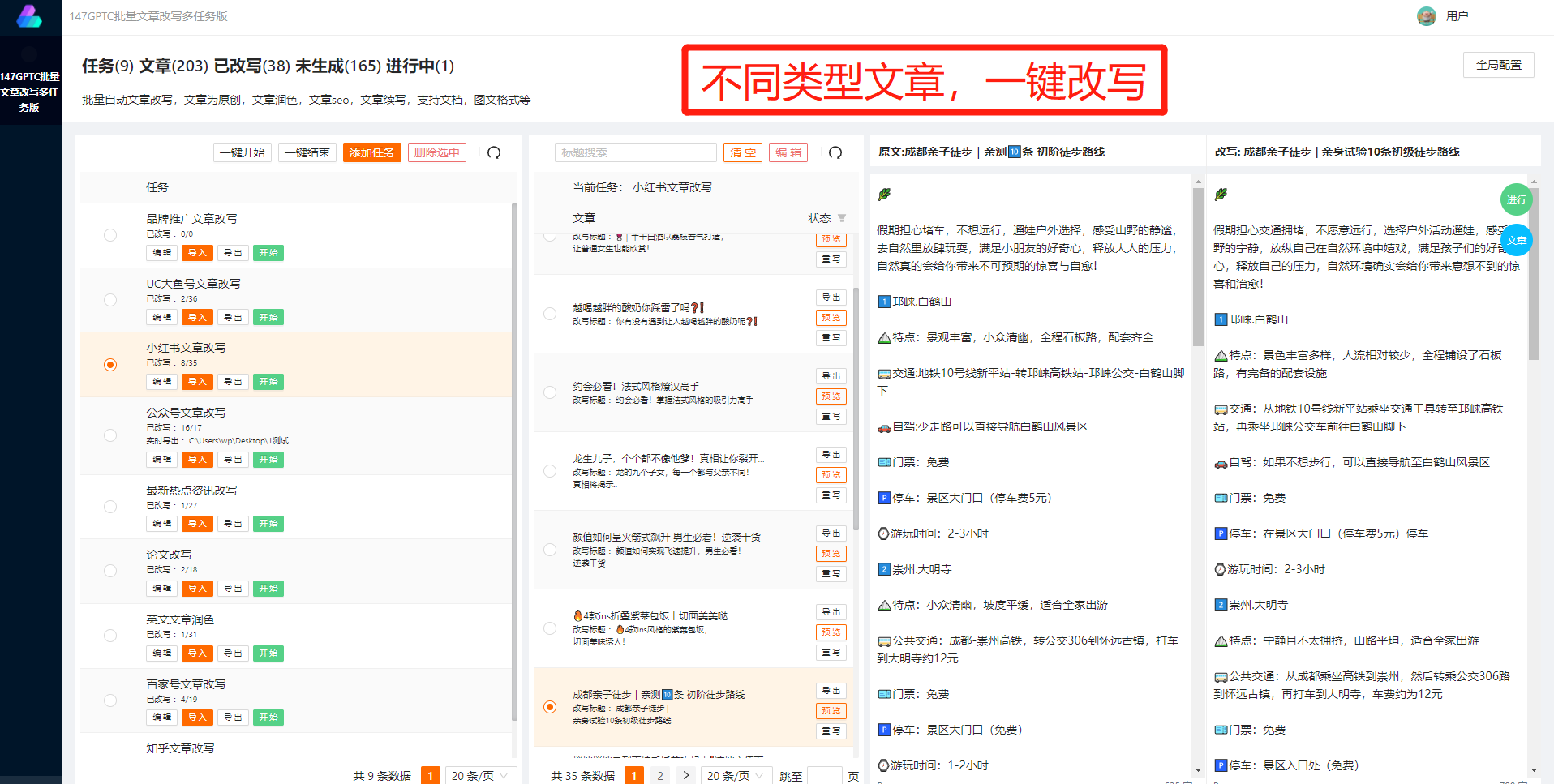
動態網頁數據的爬取本質上是模擬瀏覽器行為,通過模擬用戶的操作來獲取頁面上的數據。一種常用的方法是使用Selenium這樣的工具,它可以模擬瀏覽器的行為,并且支持多種瀏覽器,能夠很好地處理各種網頁中的動態數據。通過Selenium,我們可以指定要獲取的頁面,模擬點擊、滾動等操作,然后獲取頁面上的數據,實現動態網頁數據的爬取。
除了Selenium,還有一些其他的工具和技術可以用來爬取動態網頁數據。使用Headless瀏覽器(無頭瀏覽器)如Puppeteer,它可以在后臺運行,模擬瀏覽器操作,并且支持JavaScript渲染,能夠處理各種動態網頁。還有一些第三方API,如PhantomJS,也可以用來解決動態網頁數據爬取的問題。
動態網頁數據的爬取不僅僅是技術層面的挑戰,還涉及到一些規則和道德上的問題。在進行動態網頁數據爬取時,我們需要遵守網站的規則,不得違反網站的使用條款,不得對網站造成不必要的壓力,保護網站的合法權益。也需要尊重用戶的隱私,不得獲取和使用用戶的個人信息,做到合法、合規的數據獲取。
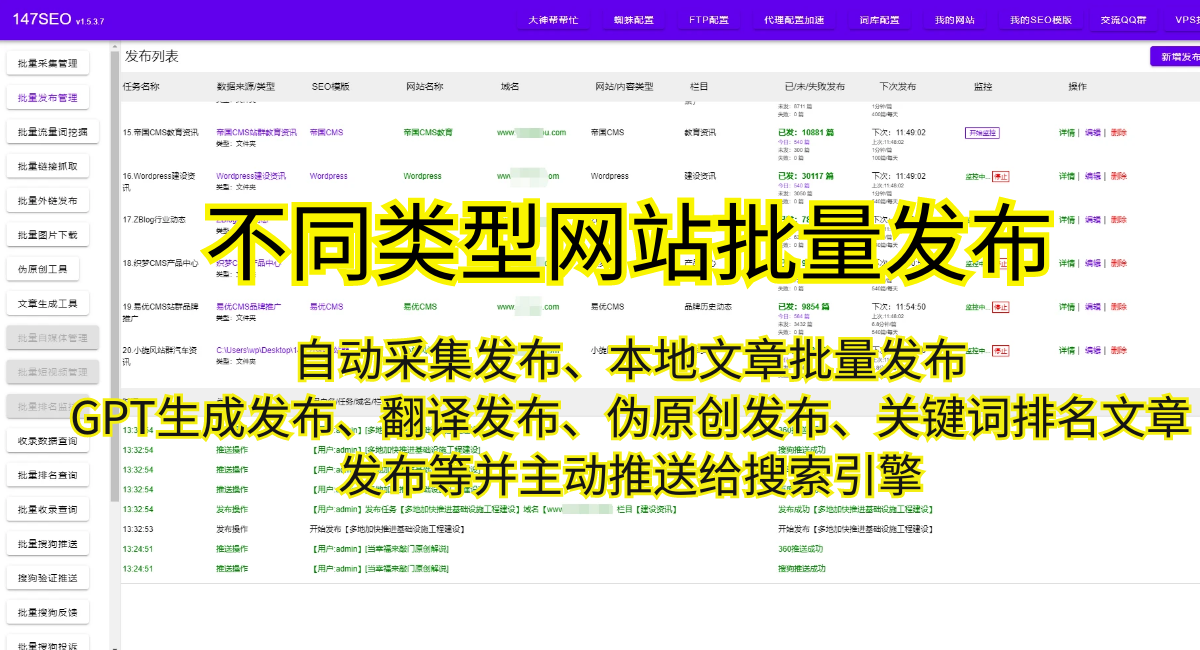
總的動態網頁數據的爬取是一項技術含量較高的工作,需要掌握一定的技術和方法。但是,一旦掌握了這項技能,我們就能夠輕松地獲取動態網頁上的數據,實現信息的快速獲取和利用。這對于數據分析、市場研究、競爭情報等方面都具有重要的意義,是一項非常有價值的技能。



