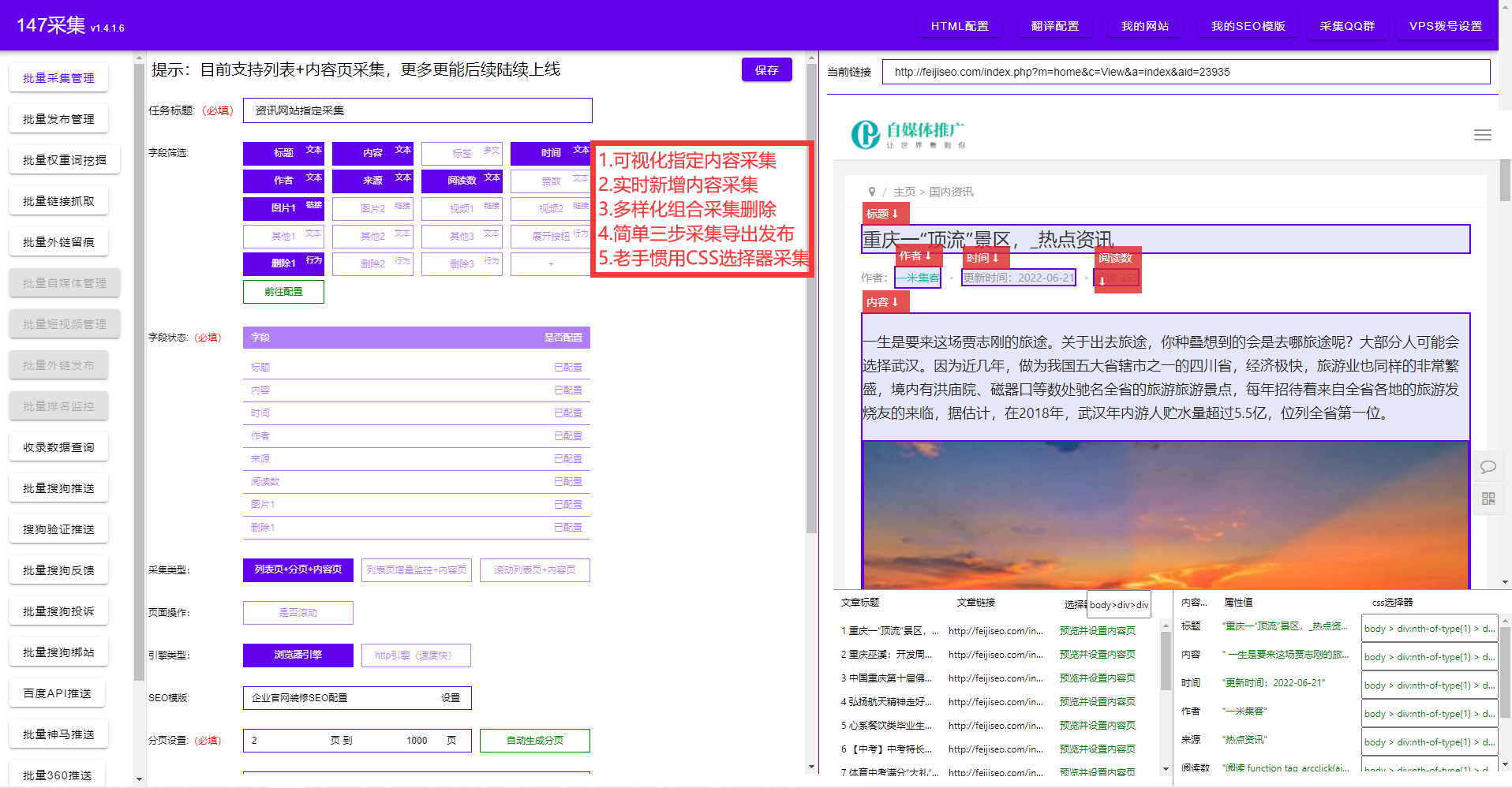
近年來,信息技術的迅猛發展催生了大量的數據,信息時代已經到來。在這個時代,掌握并利用大量的數據已經成為了企業和個人獲取競爭優勢的不二選擇。而PHP爬蟲數據采集技術的出現,為我們打開了獲取數據的大門,讓我們可以從各種網絡ZY中獲取所需的信息。
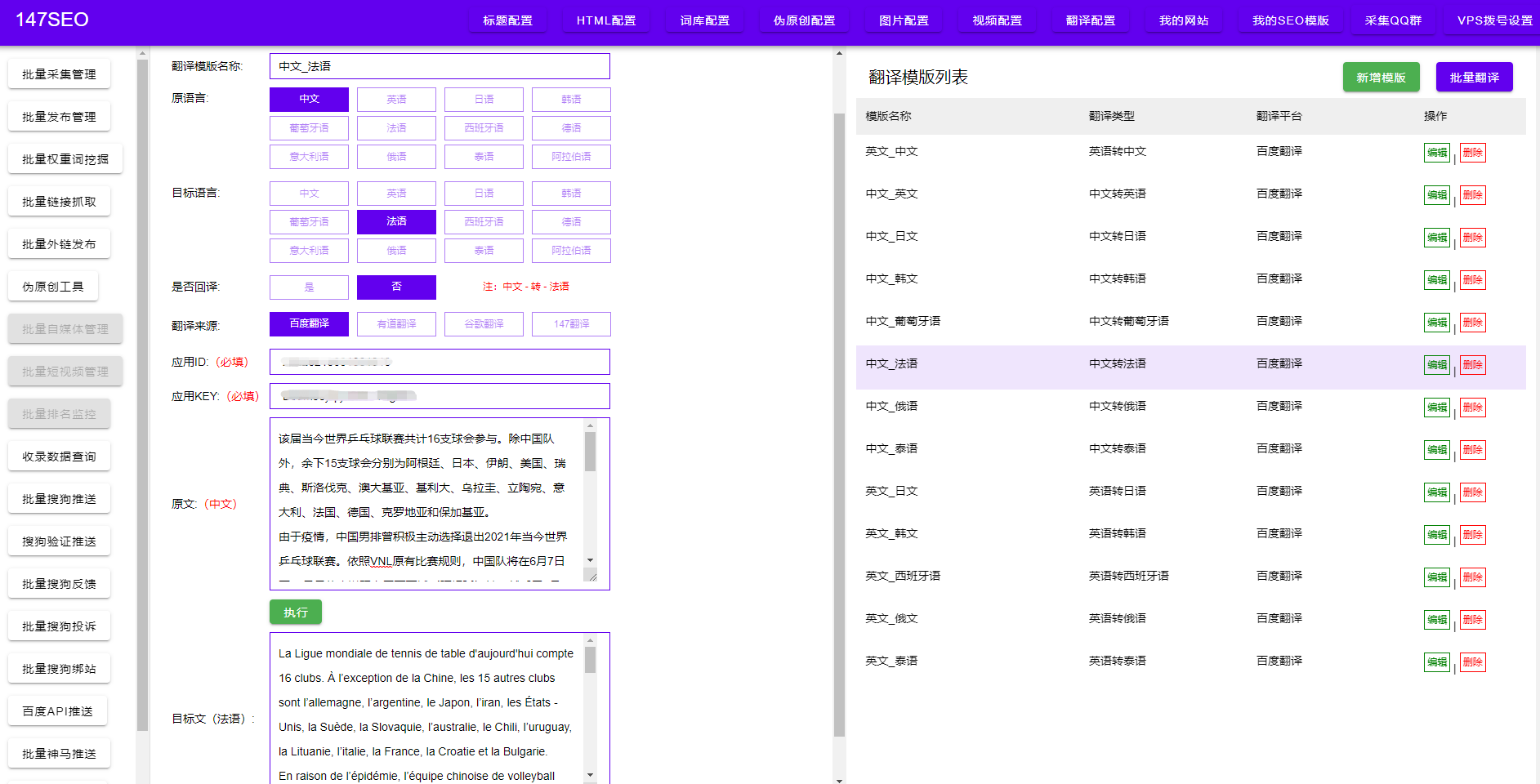
作為一種強大的編程語言,PHP被廣泛應用于開發網站和互聯網應用。而爬蟲技術,則是指通過編寫程序自動模擬人為操作,從互聯網上抓取所需數據的技術。結合PHP和爬蟲技術,我們可以輕松地編寫一個數據采集程序,幫助我們自動抓取互聯網上的數據。
首先,PHP爬蟲數據采集的基本原理是模擬瀏覽器的行為。通過模擬HTTP請求,我們可以發送請求并獲取到網頁的源代碼。然后,我們可以使用PHP內置的DOM操作函數或者第三方庫如SimpleHtmlDom來解析網頁,提取需要的數據。
其次,PHP爬蟲程序的開發需要有一定的編程基礎。我們需要掌握PHP的基礎知識,了解HTTP協議和HTML標簽的基本結構,以及熟悉一些常用的網絡庫和DOM操作函數。在開發過程中,我們需要注意遵守網絡倫理和規則規定,不要進行非法操作,避免給他人帶來損失。
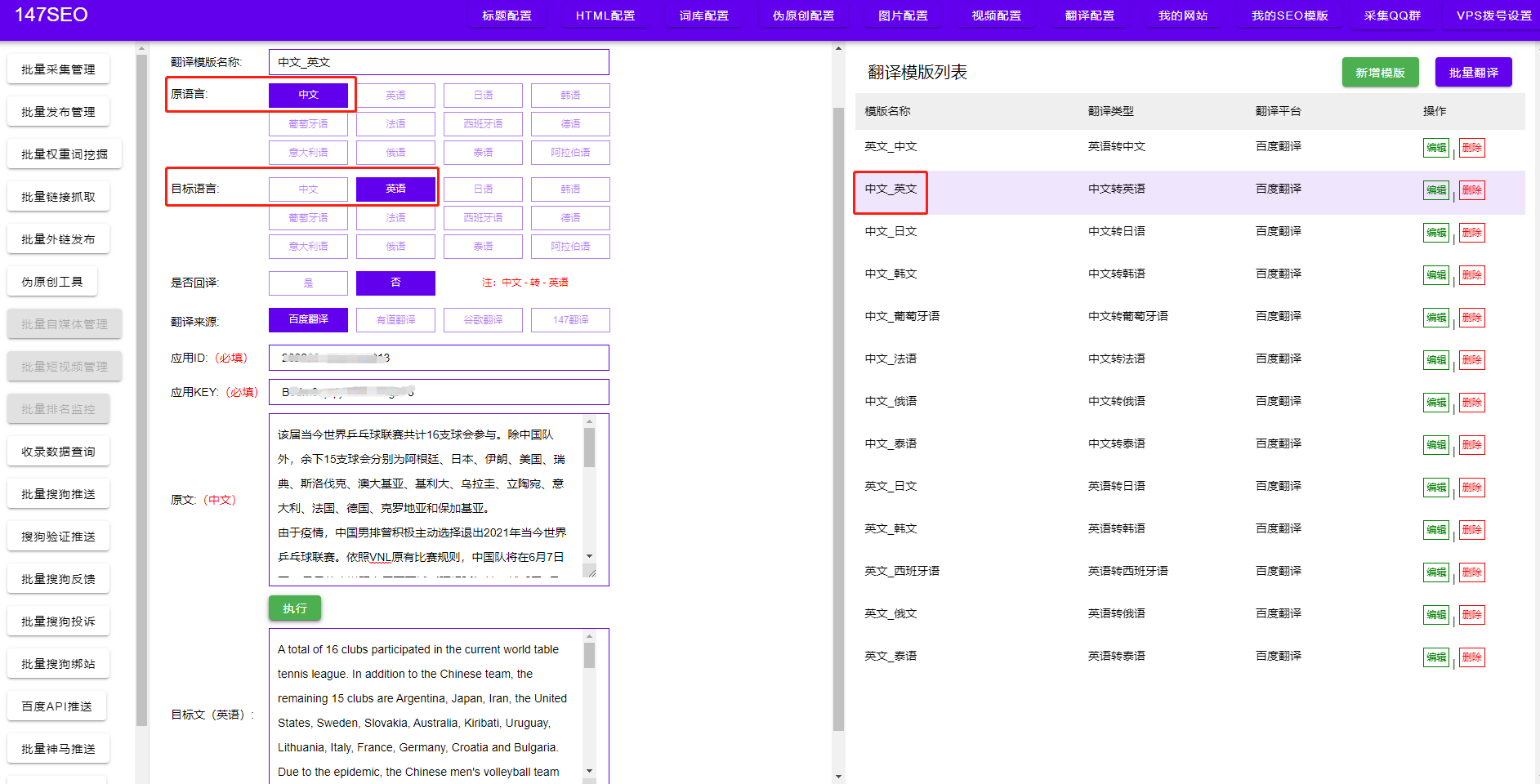
而針對不同的數據采集需求,我們可以選擇不同的爬蟲策略。常見的爬蟲策略包括基于正則表達式的爬蟲、基于XPath表達式的爬蟲和基于CSS選擇器的爬蟲。通過選擇合適的爬蟲策略,我們可以更加高效地獲取到需要的數據。
不僅如此,PHP爬蟲數據采集技術也可以應用于各種場景。例如,我們可以利用爬蟲技術進行數據分析和挖掘,幫助企業做出更加明智的決策;我們可以使用爬蟲技術監控競爭對手的動態,及時了解市場趨勢;我們還可以開發數據聚合網站,將不同來源的數據整合到一起,方便用戶查詢。
總之,PHP爬蟲數據采集技術為我們獲取到海量的數據提供了便利,開啟了信息時代的大門。利用這一技術,我們可以從互聯網中自動獲取到所需的數據,并通過分析和挖掘,為我們的工作和生活帶來更多的可能性。讓我們共同挖掘數據的價值,創造更加美好的未來!