
如何高效地抓取PDF中的數據
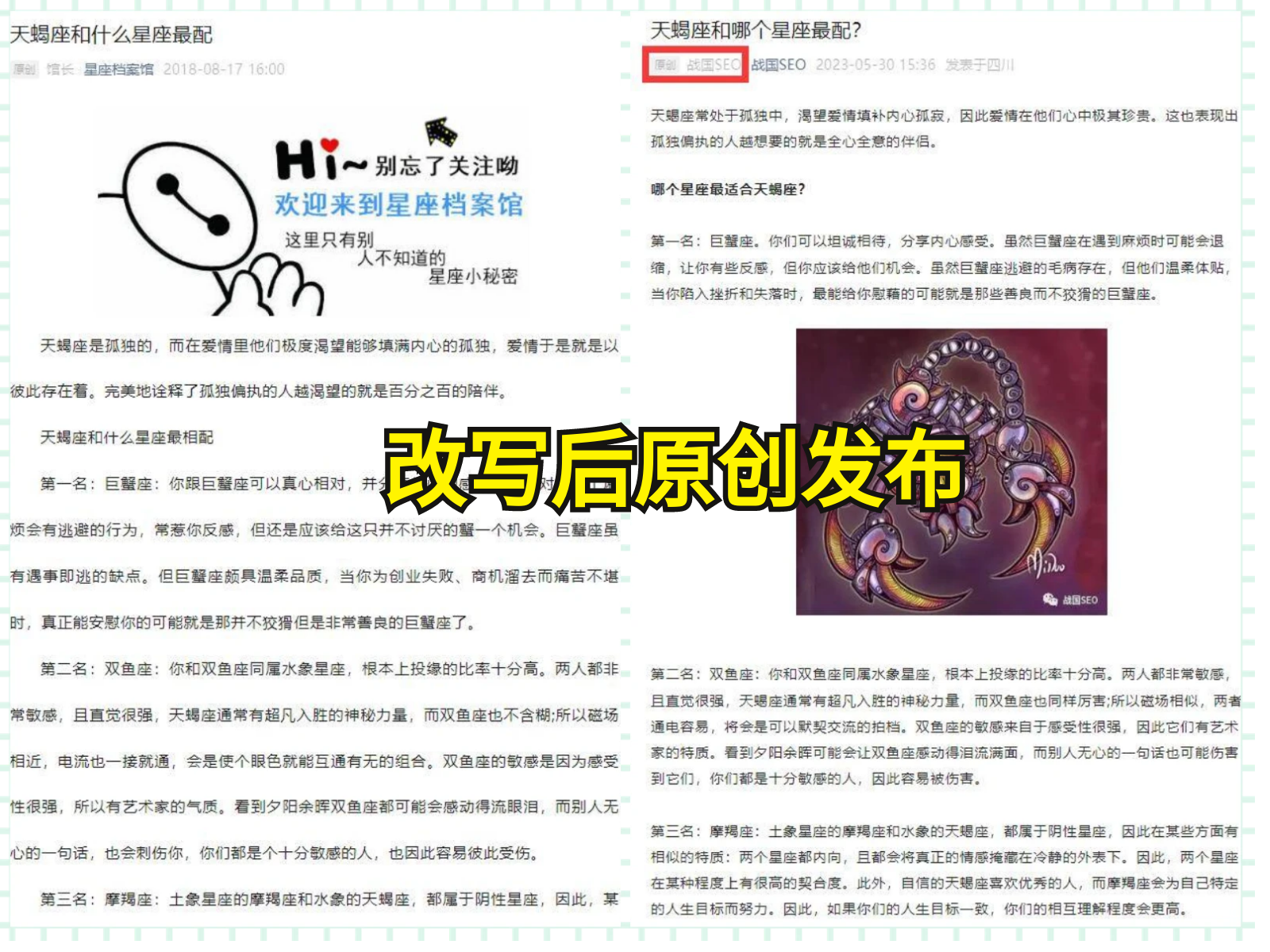
隨著互聯網技術的快速發展,大量的數據以PDF格式存儲在網絡上。然而,許多用戶需要從這些PDF文件中提取數據,以進行進一步的分析和處理。本文將為大家介紹一種簡單而有效的方法,使用技術手段快速抓取PDF中的數據。
首先,我們需要明確抓取PDF數據的目標。根據實際需求,我們可以確定需要抓取的數據類型、數據結構以及數據量。這有助于我們選擇合適的工具和方法來完成任務。
其次,我們可以借助Python編程語言的相關庫來實現PDF數據的抓取。Python擁有豐富的第三方庫,其中就包括用于處理PDF文件的庫。比如,PyPDF2、pdfminer、pdfplumber等等。這些庫能夠讀取PDF文件,并提供了各種實用的方法和函數來獲取和處理其中的數據。
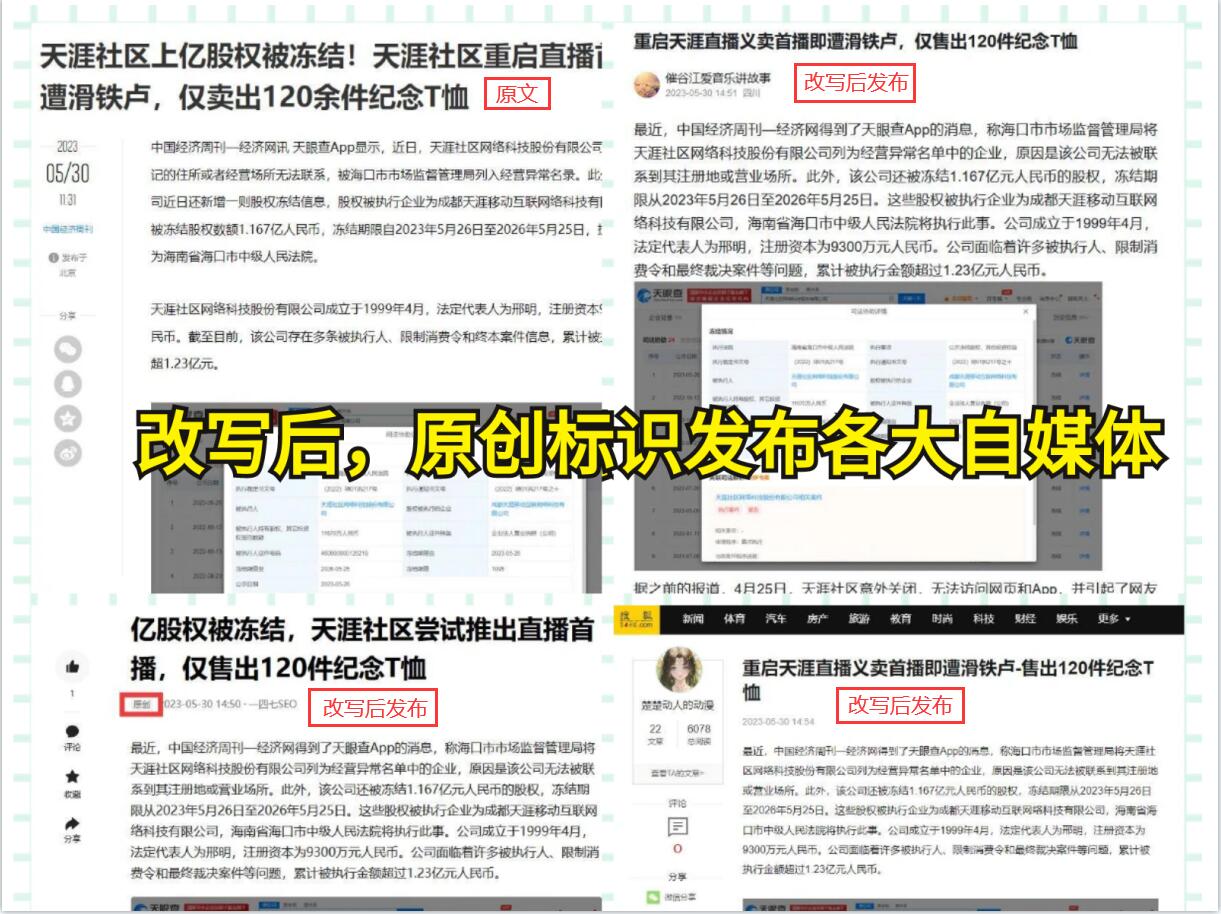
使用PyPDF2庫作為示例,我們可以使用以下代碼來實現PDF數據的抓取:
```python importPyPDF2
defextract_data_from_pdf(file_path): pdf_file=open(file_path,'rb') pdf_reader=PyPDF2.PdfReader(pdf_file) extracted_data='' forpage_numinrange(len(pdf_reader.pages)): page=pdf_reader.pages[page_num] extracted_data+=page.extract_text() pdf_file.close() returnextracted_data
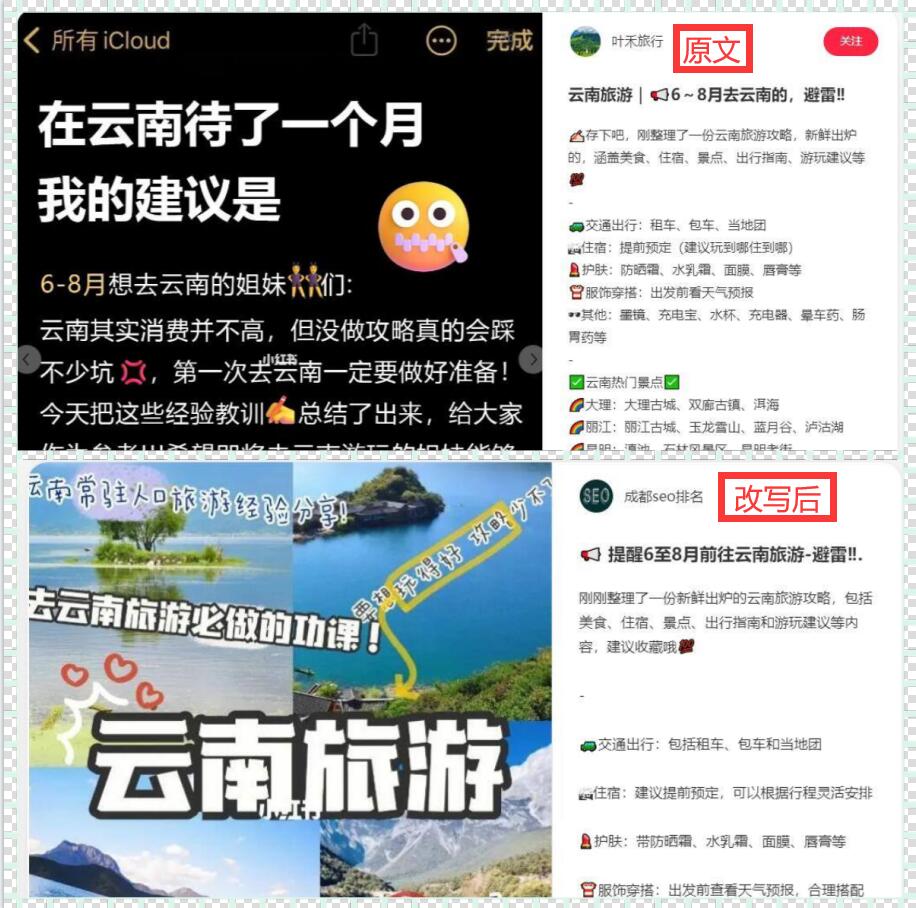
file_path='example.pdf' data=extract_data_from_pdf(file_path) print(data) ```
在上述代碼中,我們首先打開要抓取數據的PDF文件,并使用PdfReader類讀取文件內容。然后,通過遍歷每一頁,使用extract_text()方法提取每一頁的文本數據,并將其添加到extracted_data中。最后,我們關閉PDF文件并返回抓取的數據。
此外,PDF文件中的數據可能不僅僅是文本,還可能包含表格、圖片等其他格式的數據。對于這種情況,我們可以使用其他專門的庫和工具來處理。例如,使用Tabula庫來抓取PDF中的表格數據,使用textract庫來抓取PDF中的圖片數據。
總之,通過使用相關的編程庫和工具,我們可以快速而高效地抓取PDF中的數據。不論是從大量的PDF文件中提取數據,還是從復雜的PDF文件中獲取特定類型的數據,這些方法都能夠滿足我們的需求。希望本文介紹的方法能夠對大家有所幫助,讓大家能夠輕松地獲取所需的數據。



